
本文为看雪论坛优秀文章
看雪论坛作者ID:r0fm1a
众所周知,office是一个“闭源”的大型软件。广大安全研究人员针对它的研究,也多是从相应格式的官方文档,MSDN上提供的少量示例代码,乃至于有类似功能的开源软件开始的。笔者曾针对rtf文件格式做过一段时间的安全研究,在通读rtf官方文档1.9后,写过一点儿fuzz,也就知道了在只依靠官方文档的情况下,对office对rtf 格式的处理机制远远谈不到了解。为了更好的利用收集到的poc,对wwlib进行调试,所以对office负责解析rtf格式的库(wwlib.dll)进行分析。笔者选择了office 2010 professional plus 32位作为分析对象(poc比较容易获取)。本文中若干关键flag值和结构体成员的定义,参考卡巴斯基实验室2018年发布的一篇分析文章(https://securelist.com/disappearing-bytes/84017/)。
wwlib 是一个很大的动态链接库,仅就office2010的库而言,可执行文件的大小就有接近20MB,可想而知,使用IDA数据库加载以后,数据库文件会非常大。
 因为这个dll,微软没有提供调试符号,所以无论是关键函数的定位,还是关键结构体成员的定义,都存在一定难度。所以,笔者通过对不同漏洞的poc文件进行调试,根据栈回溯和参数,堆栈数据等因素,确定了wwlib解析控制字的关键函数。
因为这个dll,微软没有提供调试符号,所以无论是关键函数的定位,还是关键结构体成员的定义,都存在一定难度。所以,笔者通过对不同漏洞的poc文件进行调试,根据栈回溯和参数,堆栈数据等因素,确定了wwlib解析控制字的关键函数。

函数control_word_parsing的代码图示如上图所示,初步来看,还是有很多代码分支。函数定义和形参列表如下:int __userpurge contrl_words_parsing (RtfFormat *a1, BYTE *stream_ptr, int stream_length_stateflag, char a4)
为行文统一,本文会引用链接文章的部分信息描述函数的主要行为和功能,以便于读者进行调试。contrl_words_parsing函数状态机以及若干个状态值的定义
这个函数有一个38个状态的switch结构,卡巴斯基实验室的研究人员经过分析,对他感兴趣的部分状态给出了如下定义,同时,也给出了部分状态的伪代码。enum{ PARSER_BEGIN = 0, PARSER_CHECK_CONTROL_WORD = 2, PARSER_PARSE_CONTROL_WORD = 3, PARSER_PARSE_CONTROL_WORD_NUM_PARAMETER = 4, PARSER_PARSE_HEX_DATA = 5, PARSER_PARSE_HEX_NUM_MSB = 7, PARSER_PARSE_HEX_NUM_LSB = 8, PARSER_PROCESS_CMD = 0xE, PARSER_END_GROUP = 0x10, // …};
由于卡巴斯基实验室的作者主要研究的方向是如何检测混淆的rtf 文档,而笔者则侧重于理清wwlib解析rtf控制字的大致流程,所以对不同代码分析的侧重点有所不同。读者可以结合两篇文章一起看。PARSER_BEGIN:逐字节地读取rtf 文件流,并根据每个字节(字符)的不同,指定下一次循环需要执行的状态分支;PARSER_CHECK_CONTROL_WORD:检查文件流中当前字符的位置,以判断当前循环处理的对象是控制字的开头,还是一个控制字,并根据结果设置下一次循环的状态分支;PARSER_PARSE_CONTROL_WORD && PARSER_PARSE_CONTROL_WORD_NUM_PARAMETER:在RtfFormat(笔者自定义)对象的缓冲区中保存解析的控制字的内容,(在office 2010版本中,具体偏移为RtfFormat 第一个成员指针的偏移0x12c处,下文调试过程中会给出调试验证结果)PARSER_PARSE_HEX_DATA PARSER_PARSE_HEX_NUM_MSB和PARSER_PARSE_HEX_NUM_LSB三个状态 主要对应的是解析十六进制数据,包括hex流的转码以及不同值的处理,上面对不同状态的说明,笔者可以参考。
office 2010 解析控制字命令的具体实现
笔者最关注的状态,是在default case中的case 14,也就是PARSER_PROCESS_CMD,当解析器成功的解析一个完整的控制字(包括数字参数以及pcdata,bindata 等后续数据)后,state_flag 会被设置成0x15,也就是默认状态,同时将RtfFormat 对象的第一个成员(rtf_doc, 笔者自定义)偏移为2的字节设为PARSER_PROCESS_CMD, PARSER_END_GROUP等值,便于下次循环跳转到相应的状态。
default case 的代码如下图所示:
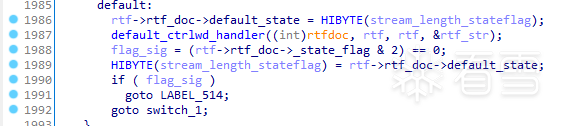
default_ctrlwd_handler 函数结构如下所示:
rtf_doc为RtfFormat对象的第一个成员类型,我们可以看到,这是一个成员非常多的类型,现提供部分自定义的成员如下:
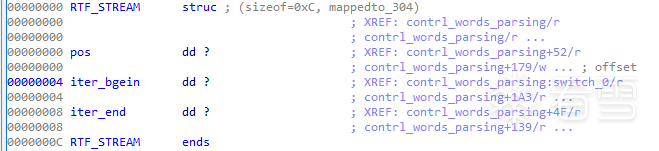
RTF_STREAM是用来解析rtf数据流控制字时使用的结构:
 将wwlib解析rtf格式的对象自命名为RtfFormat, 则rtf_doc是RtfFormat对象的第一个成员,我们可以看到,这是一个成员非常多的类型,现提供部分自定义的成员如下:
将wwlib解析rtf格式的对象自命名为RtfFormat, 则rtf_doc是RtfFormat对象的第一个成员,我们可以看到,这是一个成员非常多的类型,现提供部分自定义的成员如下:
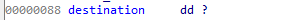
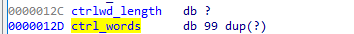
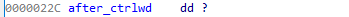
偏移0x88 的destination成员是一个非常重要的成员,表明destination类型控制字(具体参考rtf文件格式规范的相关定义)的destination的值。偏移0x12c的单字节成员表明当前需要解析的控制字的长度,后面的一个C风格字符串成员,是控制字和可能的数字参数,以‘\0’分隔。
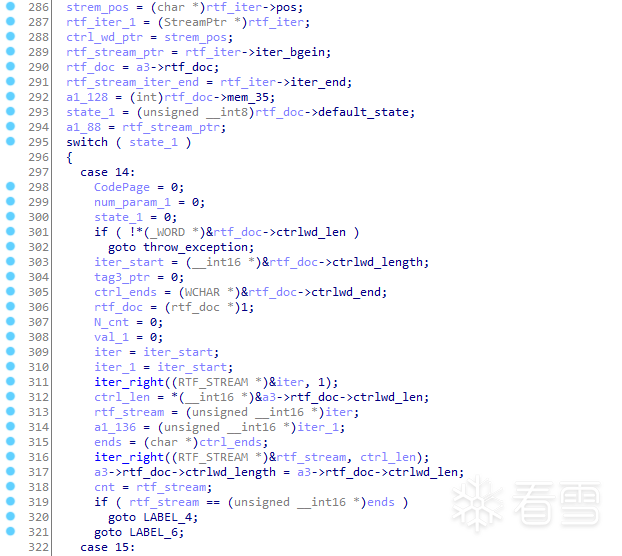
简单来说,这段代码的功能为:读取传入的RtfFormat对象和用于迭代的Rtf_Stream对象成员,获取控制字字符部分以及cnt部分的指针。
首先需要判断控制字是否存在数字参数,如果存在的话,需要提取参数的值,然后调用get_ctrl_index函数,得到控制字在wwlib给定的rtf控制字列表中的索引值。office rtf控制字列表按照ascii码进行字典排序,用一个元组的list 维护字典索引。按照ascii排序给定一个元组的list,假设索引为m的元组值为(a, b),则表示ascii值为m的字符,在控制字列表的索引范围为[a, b)。比如list[97] = (9, 4A), 就代表以‘a’打头的控制字,在控制字列表的下标区间是[9, 0x4a)。首先获取控制字首字母,然后查表,获取首尾索引值,然后用二分查找,匹配相应索引的控制字,最后返回该控制字对应的索引值。对于混淆的控制字和错误的控制字信息,会有相应的处理机制。关于上图中ctrlwd_index_value与1775的比较,是因为在office 2010 参照的rtf的版本,一共有1775个控制字,对于异常值,会相应处理。
获取到控制字的有效偏移后,通过读取traid_tag_list的相应偏移,得到一个三元组:

通过dump控制字列表和三元组的信息,可以得到一张表,部分内容如下所示:
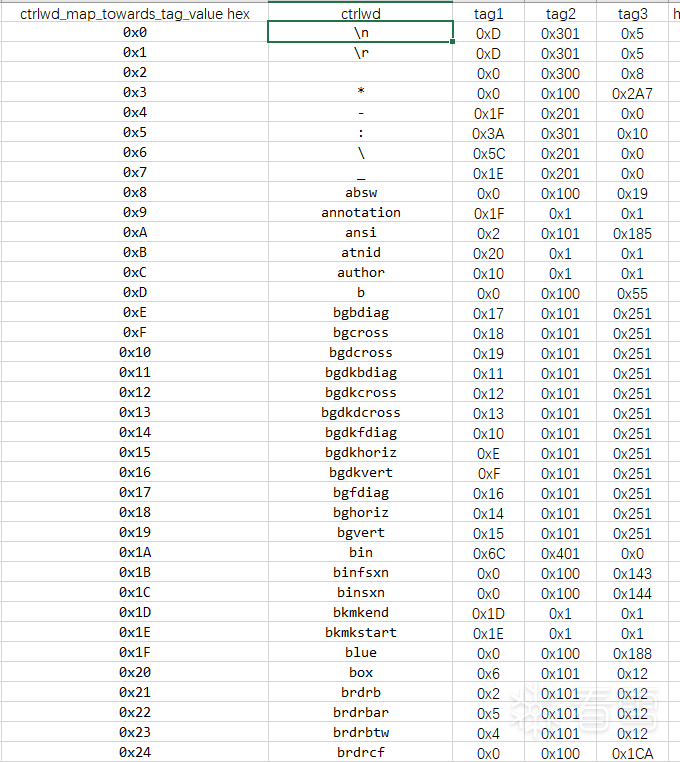
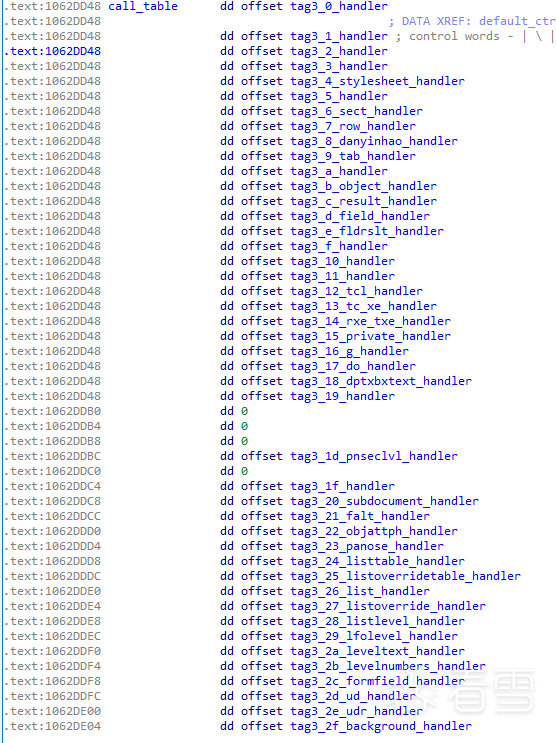
wwlib就是根据解析得到的控制字和三元组的对照,根据每个控制字的的属性执行不同的代码。其中,tag1的值会作为实参传入控制字相关的handler函数当中,可能会被赋值给destination,也可能是其他值,这个根据每个handler的情况而定。当需要调用ctrlwd对应的handler函数时,tag3作为handler列表的索引,用来获取函数指针。1175个控制字的tag2 高字节,取值范围为0-7,下面代码所示,当高字节为0或3时,会通过tag3的值寻找相应函数,执行相应的代码。在office 2010 定义的所有控制字中,tag2 高字节为0 或3 的,共有82个,在ida 给部分handler下的注释如下所示:
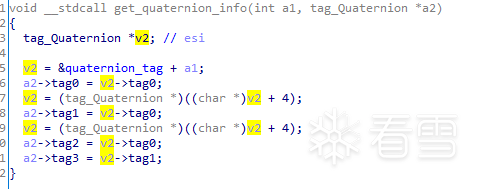
 当tag2 的高字节值为1时,则会通过调用tag2_hibyte_1_handler这个函数,给根据控制字和数字参数,hex_data,字符串参数等值,进行不同的操作。在这个函数中,需要通过三元组的tag3 为索引,在wwlib提供的数据里,查找到一个四元组。获取四元组后,会根据属性值的不同,跳转到不同的处理分支。
当tag2 的高字节值为1时,则会通过调用tag2_hibyte_1_handler这个函数,给根据控制字和数字参数,hex_data,字符串参数等值,进行不同的操作。在这个函数中,需要通过三元组的tag3 为索引,在wwlib提供的数据里,查找到一个四元组。获取四元组后,会根据属性值的不同,跳转到不同的处理分支。
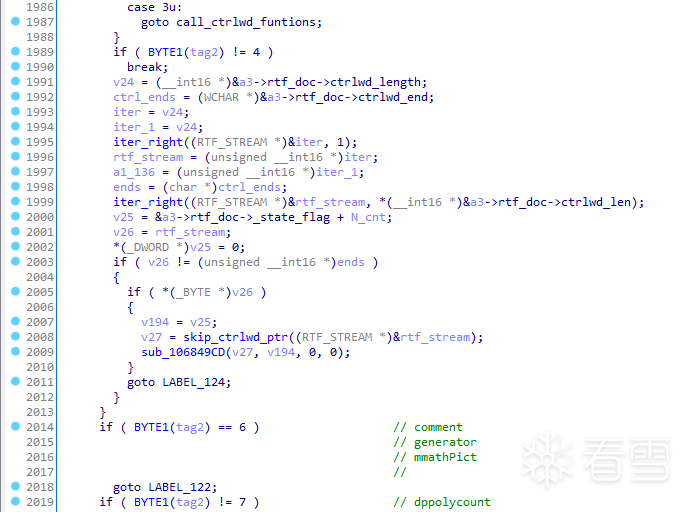
 这个函数主要以四元组的tag0的高低字节的值执行不同的代码流程,其中,tag0 高字节的switch结构,主要是根据不同的值,为RtfFormat对象的不同成员赋值。而tag0 低字节的switch结构,功能就相对丰富一些。其他的分支相对简单,这里讨论当tag0 的低字节为7时的929个case。
这个函数主要以四元组的tag0的高低字节的值执行不同的代码流程,其中,tag0 高字节的switch结构,主要是根据不同的值,为RtfFormat对象的不同成员赋值。而tag0 低字节的switch结构,功能就相对丰富一些。其他的分支相对简单,这里讨论当tag0 的低字节为7时的929个case。
每一个case 都通过tag3 的值关联到控制字的属性。至于每一个case的功能,则需要具体分析了。
以上即是wwlib解析rtf格式的大致逻辑,基本上就是围绕微软根据控制字属性定义的三元组和四元组的值进行判断,并执行不同的代码来完成整个rtf格式文档的解析。感兴趣的同学可以自行调试,如果能找到合适的rtf格式漏洞的poc,相信调试的思路会稍微清晰一些。
笔者简单对照了office 2013 及更高的版本,由于控制字的数量有所增加,以及代码架构调整,所以控制字关联的三元组和四元组信息会有所变化,但整体思路没有很大的改变。看雪ID:r0fm1a
https://bbs.pediy.com/user-home-838258.htm
*本文由看雪论坛 r0fm1a 原创,转载请注明来自看雪社区
在线申请SSL证书行业最低 =>立即申请
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 关注KnowSafe微信公众号
关注KnowSafe微信公众号



