人工智能竞赛-房价预测


本文为看雪论坛优秀文章
看雪论坛作者ID:pureGavin
我的代码
# This Python 3 environment comes with many helpful analytics libraries installed# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python# For example, here's several helpful packages to loadimport numpy as np # linear algebraimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)from sklearn.ensemble import RandomForestRegressor# Input data files are available in the read-only "../input/" directory# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directoryimport osfor dirname, _, filenames in os.walk('/kaggle/input'):for filename in filenames:print(os.path.join(dirname, filename))# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session# 载入训练数据train=pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/train.csv')train.head()# 选取部分训练数据train_y=train.SalePricepredict_data=['LotArea','OverallQual','YearBuilt','YearRemodAdd','GrLivArea','TotRmsAbvGrd']train_X=train[predict_data]# 进行训练model=RandomForestRegressor()model.fit(train_X,train_y)# 载入测试数据,并进行预测test=pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/test.csv')test_X=test[predict_data]predict_price=model.predict(test_X)print(predict_price)# 输出成表格的形式并提交my_submission=pd.DataFrame({'Id':test.Id,"SalePrice":predict_price})#my_submission.head()my_submission.to_csv("submission.csv",index=False)

大神的代码
#invite people for the Kaggle partyimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport numpy as npfrom scipy.stats import normfrom sklearn.preprocessing import StandardScalerfrom scipy import statsimport warningswarnings.filterwarnings('ignore')%matplotlib inline#bring in the six packsdf_train = pd.read_csv('./input/train.csv')#check the decorationdf_train.columns
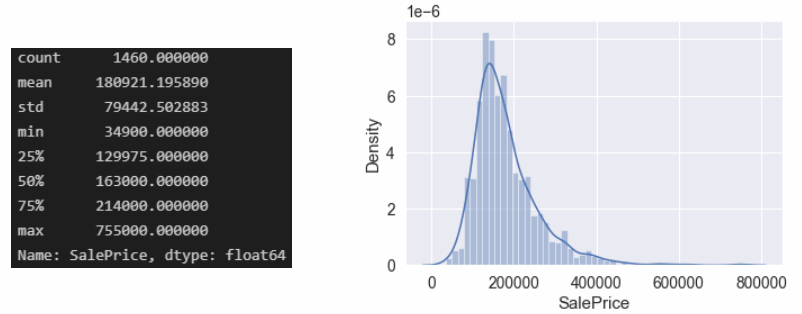
# 打印出saleprice的分布df_train['SalePrice'].describe()# 使用图表打印出saleprice的分布情况sns.distplot(df_train['SalePrice']);#skewness and kurtosisprint("Skewness: %f" % df_train['SalePrice'].skew())print("Kurtosis: %f" % df_train['SalePrice'].kurt())
# 检查grlivarea与saleprice的关系,这两组数值有线性关系var = 'GrLivArea'data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));

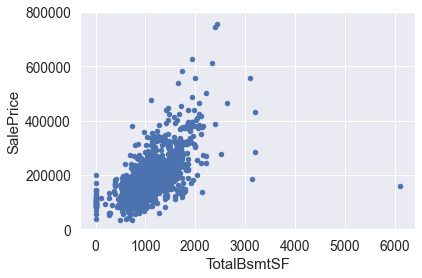
# 检查totalbsmtsf与saleprice的关系,这两组数据也有线性关系,但在某些情况下totalbsmtsf会直接归零var = 'TotalBsmtSF'data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));
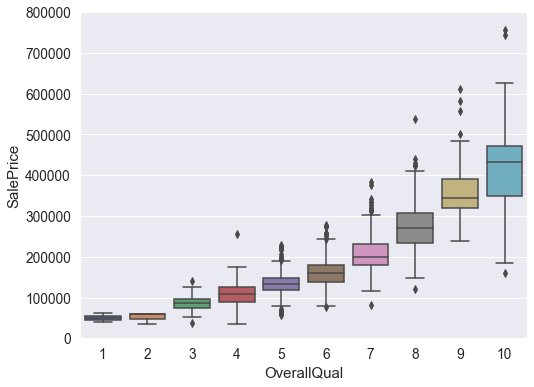
# 检查overallqual与saleprice的关系,也是线性关系,但每个阶段都有异常值# 分析这两组数据之间的关系用的是箱型图var = 'OverallQual'data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)f, ax = plt.subplots(figsize=(8, 6))fig = sns.boxplot(x=var, y="SalePrice", data=data)fig.axis(ymin=0, ymax=800000);
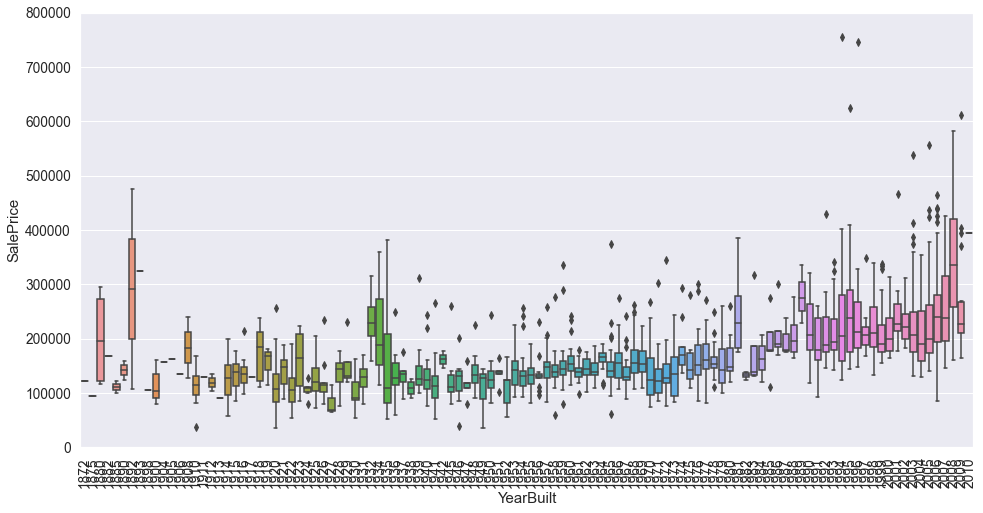
# 建造年份与售价的关系图,可见并没有多少关系,并且这组走向数据并没有考虑到通货膨胀的问题var = 'YearBuilt'data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)f, ax = plt.subplots(figsize=(16, 8))fig = sns.boxplot(x=var, y="SalePrice", data=data)fig.axis(ymin=0, ymax=800000);plt.xticks(rotation=90);
# 上面我们只选择了几个关联的特征,然而这么做是不严谨的,因为这样就会把潜在可能影响saleprice的特征全部忽略# 热力图用来表示数据与数据之间的关系,这张热力图包含了训练数据中所有的项目,并且颜色越浅表示关联越大corrmat = df_train.corr()f, ax = plt.subplots(figsize=(15, 10))sns.heatmap(corrmat, vmax=.8, square=True,linewidths=0.2);

# 将上面的热力图中的数据进行筛选,选出十个与售价关系最大的特征并重新组成一张热力图k = 10 #number of variables for heatmapcols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].indexcm = np.corrcoef(df_train[cols].values.T)sns.set(font_scale=1.25)hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f',annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values,linewidths=0.2)plt.show()

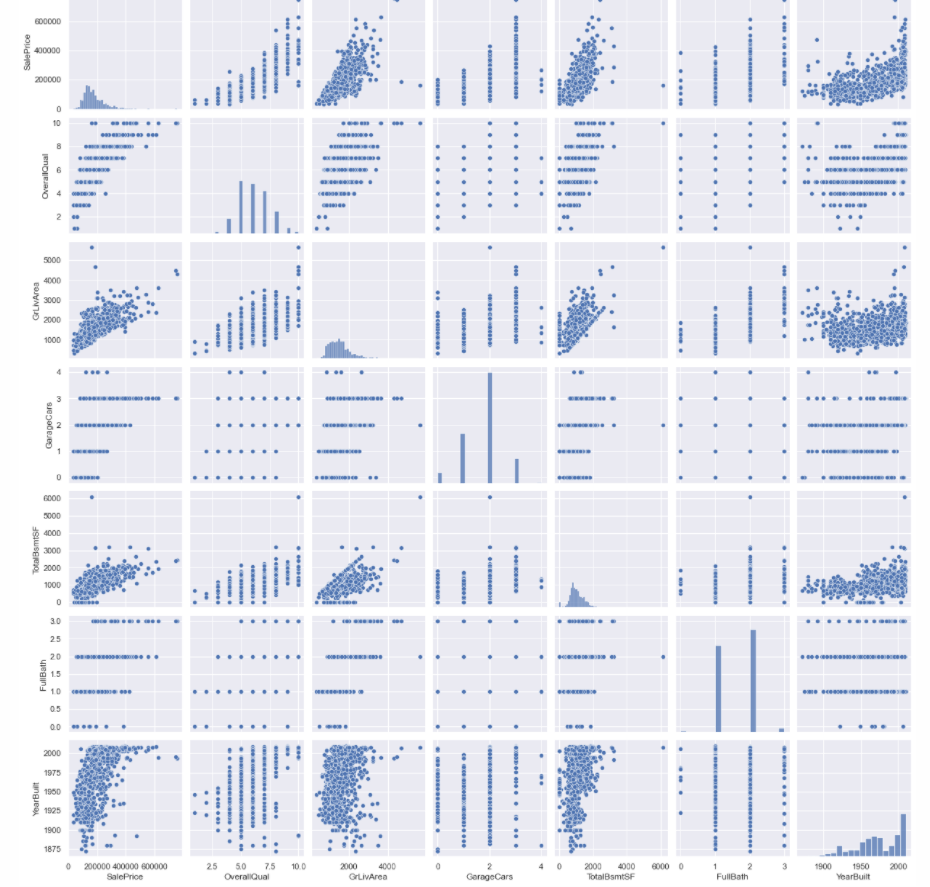
# 将上面的热力图改为散点图sns.set()cols = ['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath', 'YearBuilt']sns.pairplot(df_train[cols], size = 2.5)plt.show();
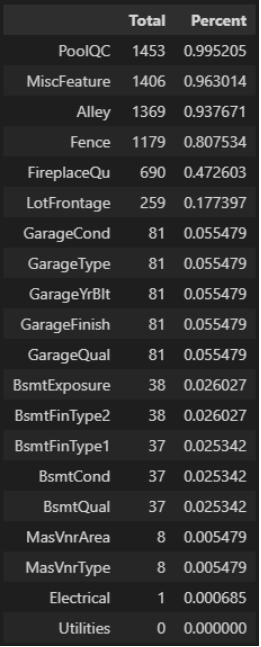
# 打印出数据缺失的情况total = df_train.isnull().sum().sort_values(ascending=False)#print(total.head(20))percent = (df_train.isnull().sum()/df_train.isnull().count()).sort_values(ascending=False)missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])missing_data.head(20)
# 处理缺失的数据df_train = df_train.drop((missing_data[missing_data['Total'] > 1]).index,1)df_train = df_train.drop(df_train.loc[df_train['Electrical'].isnull()].index)# 检查是否还有缺失的数据df_train.isnull().sum().max()
# 对数据中的离群值进行处理,低范围的值都差不多,但是高范围的值相差很多,需要着重注意一下最高的两个7saleprice_scaled = StandardScaler().fit_transform(df_train['SalePrice'][:,np.newaxis]);low_range = saleprice_scaled[saleprice_scaled[:,0].argsort()][:10]high_range= saleprice_scaled[saleprice_scaled[:,0].argsort()][-10:]print('outer range (low) of the distribution:')print(low_range)print('\nouter range (high) of the distribution:')print(high_range)

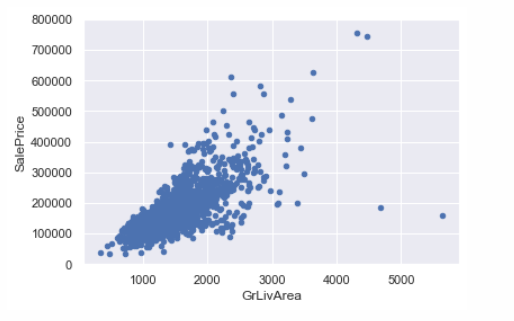
# 观察grlivarea与saleprice的关系,可以看到grlivarea有两个特别大的值但是saleprice都不高,应当认定为离群值,需要删除# 但是顶部的两个值虽然看似离群值,但是是顺应趋势的,需要保留var = 'GrLivArea'data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));
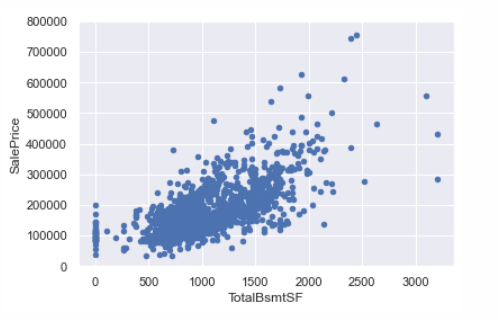
# 删除grlivarea中的离群值df_train.sort_values(by = 'GrLivArea', ascending = False)[:2]df_train = df_train.drop(df_train[df_train['Id'] == 1299].index)df_train = df_train.drop(df_train[df_train['Id'] == 524].index)# 打印totalbsmtsf与saleprice的关系,有三个大于三千的值,但是不需要处理,对于离群值的处理需要谨慎,并不是看到就删除var = 'TotalBsmtSF'data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));
# 打印出直方图和正态概率图sns.distplot(df_train['SalePrice'], fit=norm);fig = plt.figure()res = stats.probplot(df_train['SalePrice'], plot=plt)
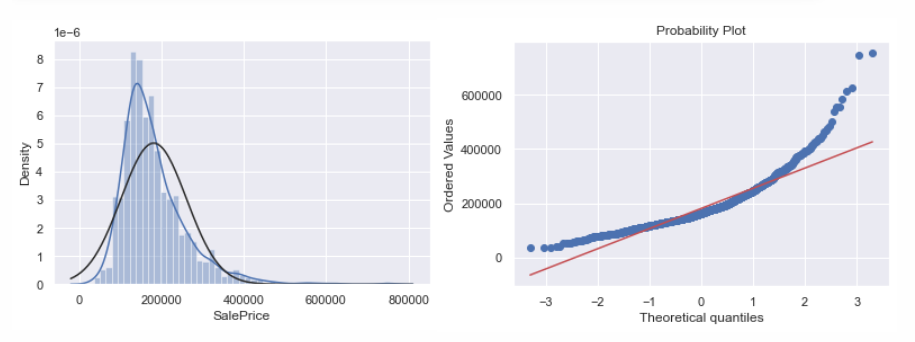
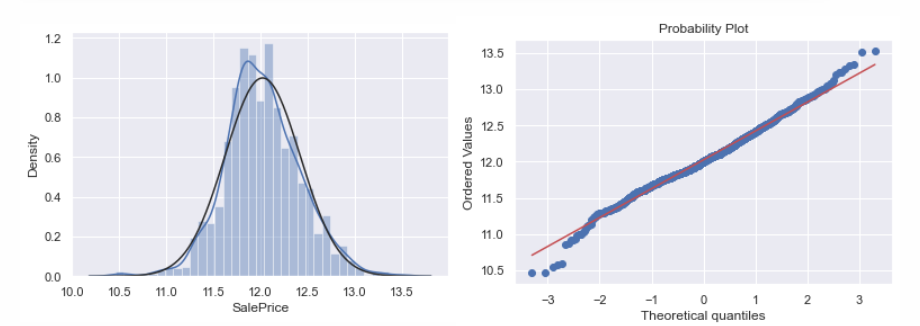
# 应用对数变换df_train['SalePrice'] = np.log(df_train['SalePrice'])# 变换后的直方图和正态概率图sns.distplot(df_train['SalePrice'], fit=norm);fig = plt.figure()res = stats.probplot(df_train['SalePrice'], plot=plt)
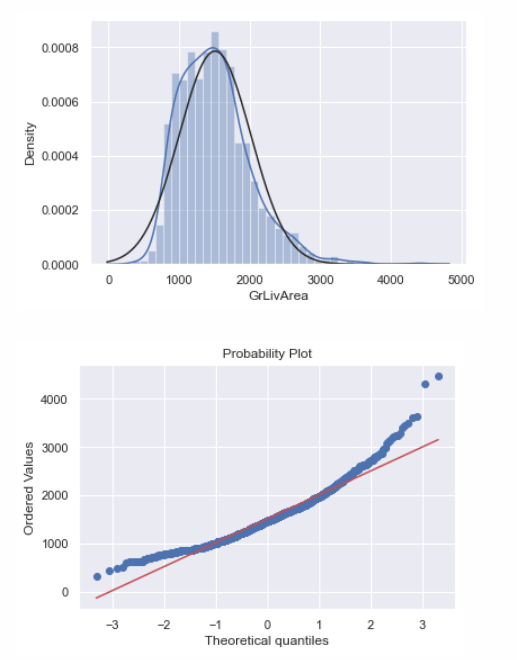
# grlivarea在对数变换前的直方图和正态概率图sns.distplot(df_train['GrLivArea'], fit=norm);fig = plt.figure()res = stats.probplot(df_train['GrLivArea'], plot=plt)
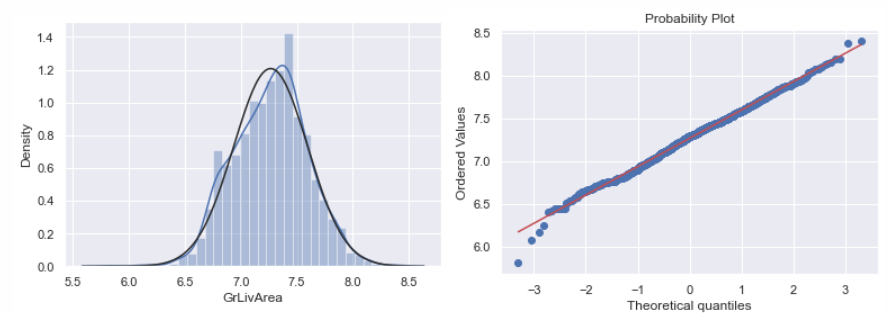
# 应用对数变换df_train['GrLivArea'] = np.log(df_train['GrLivArea'])# grlivarea做了对数变换后的直方图和正态概率图sns.distplot(df_train['GrLivArea'], fit=norm);fig = plt.figure()res = stats.probplot(df_train['GrLivArea'], plot=plt)
# totalbsmtsf在做对数转换前的直方图和正态概率图sns.distplot(df_train['TotalBsmtSF'], fit=norm);fig = plt.figure()res = stats.probplot(df_train['TotalBsmtSF'], plot=plt)
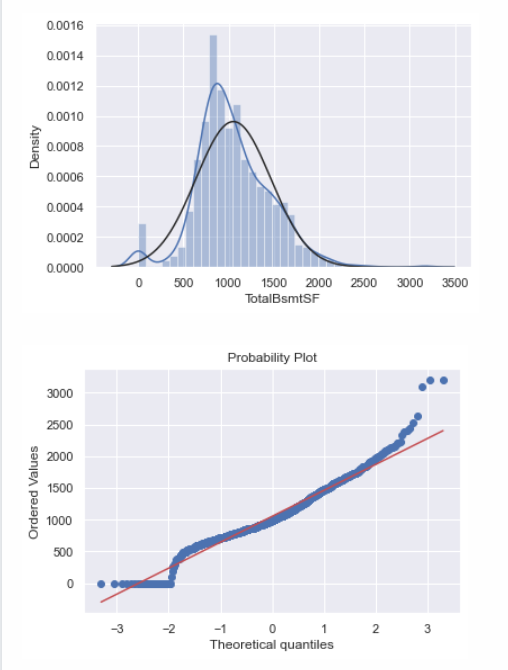
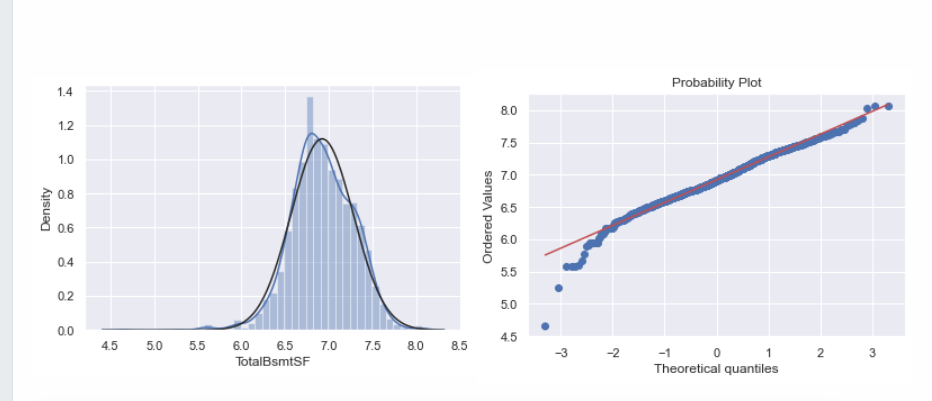
# totalbsmtsf这项数据有些特殊,因为有很多0值,而0是没有对数的,所以不能进行对数转换# 但是有许多非零的值是可以转换的,所以我们需要暂时忽略零值df_train['HasBsmt'] = pd.Series(len(df_train['TotalBsmtSF']), index=df_train.index)df_train['HasBsmt'] = 0df_train.loc[df_train['TotalBsmtSF']>0,'HasBsmt'] = 1# 应用对数变换df_train.loc[df_train['HasBsmt']==1,'TotalBsmtSF'] = np.log(df_train['TotalBsmtSF'])# 转换后的方直图和正态概率图sns.distplot(df_train[df_train['TotalBsmtSF']>0]['TotalBsmtSF'], fit=norm);fig = plt.figure()res = stats.probplot(df_train[df_train['TotalBsmtSF']>0]['TotalBsmtSF'], plot=plt)
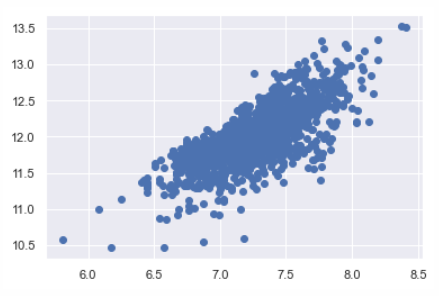
# 之前的grlivarea与saleprice的图是类似于圆锥的形状(同质问题严重)# 做了正态处理后,散点图就不再有圆锥型状了(解决了同质问题)plt.scatter(df_train['GrLivArea'], df_train['SalePrice']);
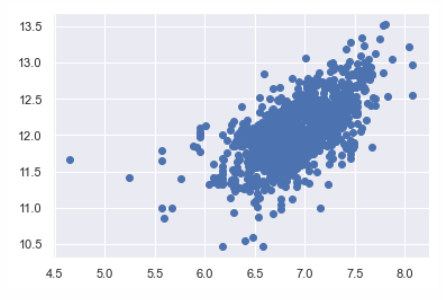
# 对totalbsmtsf做正态处理后,同质问题也得到了解决plt.scatter(df_train[df_train['TotalBsmtSF']>0]['TotalBsmtSF'], df_train[df_train['TotalBsmtSF']>0]['SalePrice']);
# 将分类变量转换为虚拟变量df_train = pd.get_dummies(df_train)

看雪ID:pureGavin
https://bbs.pediy.com/user-home-777502.htm

# 往期推荐

球分享
球点赞
球在看

点击“阅读原文”,了解更多!
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注KnowSafe微信公众号
关注KnowSafe微信公众号随时掌握互联网精彩
- Setapp自4月25日停止家庭版计划 无法再通过家庭版拼车订阅软件
- 如何高效实现 MySQL 与 elasticsearch 的数据同步
- 在Z|广州期货交易所诚招网络安全岗
- 有自带Buff的专属摄影师是种什么体验?
- 快1倍,我在 M1 Max 上开发 iOS 应用有了这些发现
- 高朋满座话未来|专访荣耀终端有限公司产品线总裁方飞
- “霸道黑客改了我的大纲”,嫌作者写得太烂,粉丝盗号写两万字新剧情
- 用 Python 实现隐身,我可以
- 北上广,是程序员最好的归宿?
- 高朋满座话未来|专访OPPO创始人兼首席执行官陈明永
- 网上诈骗为何如此泛滥?360:你要的诈骗方式我都有!
- SSL证书竟然会影响智能电视和冰箱?
赞助链接








