某APP加固产品的深入分析

本文为看雪论坛精华文章
看雪论坛作者ID:卧勒个槽
样本
应用宝随手下载一个安装包,本文分析的是作业帮v13.28.0。
工具
jadx、idapro、unicorn。
分析

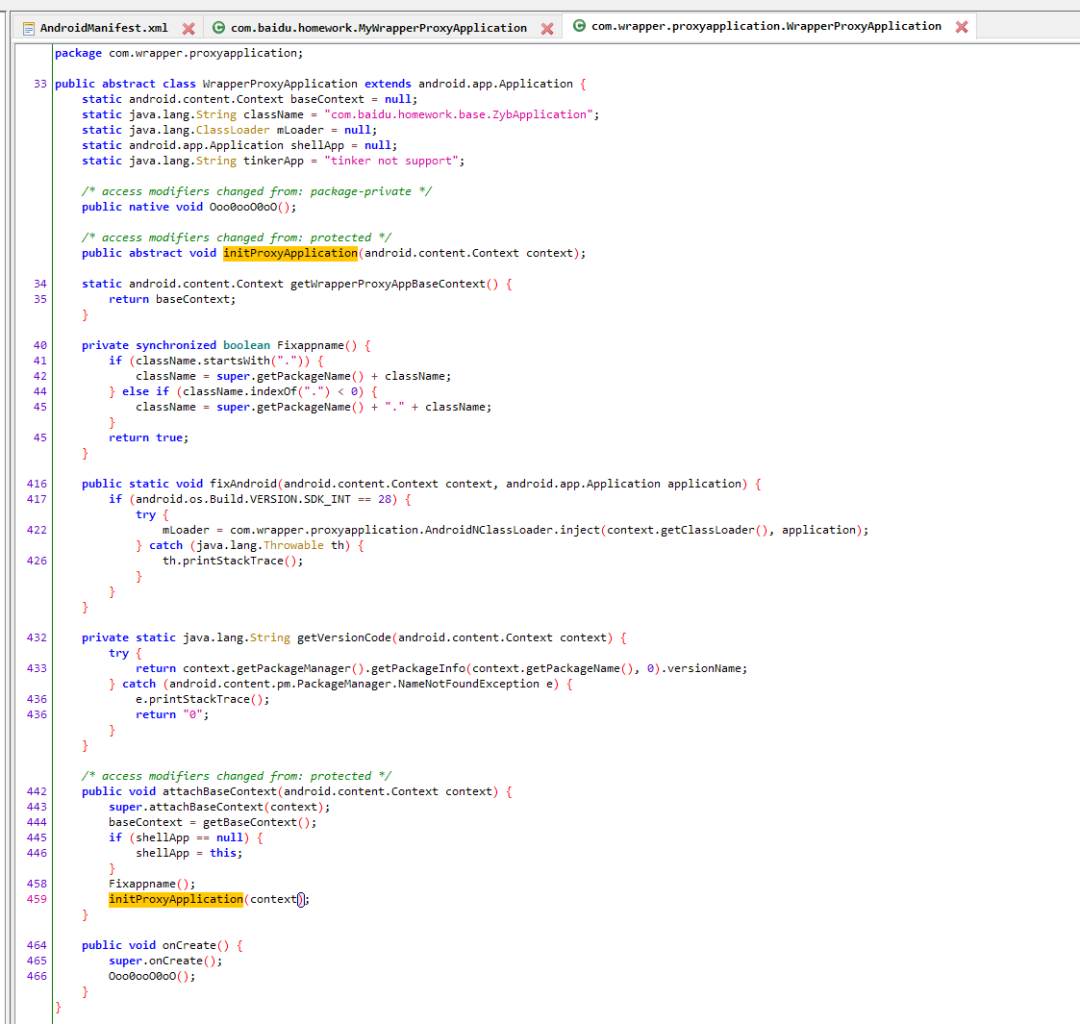

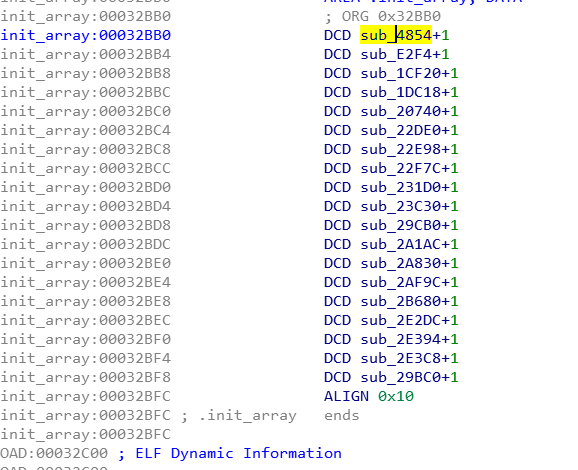
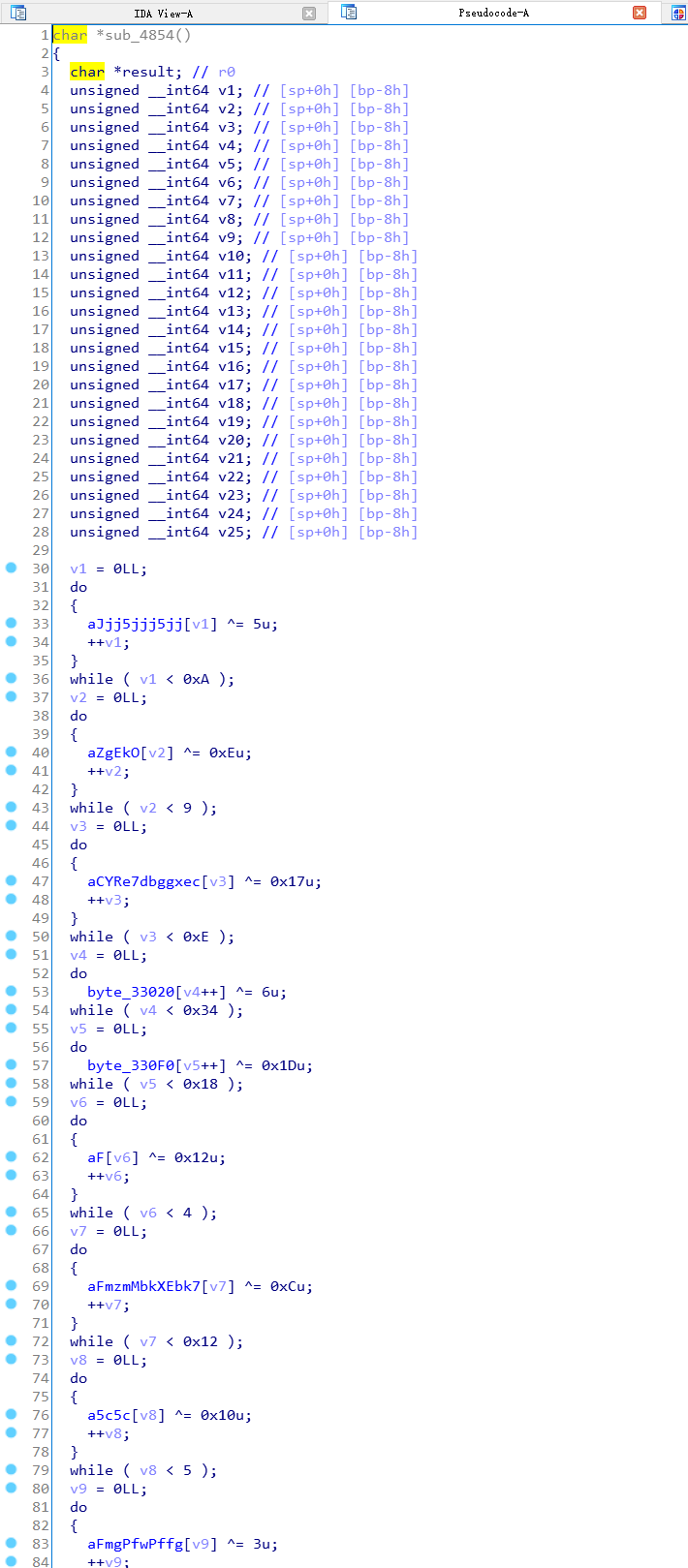
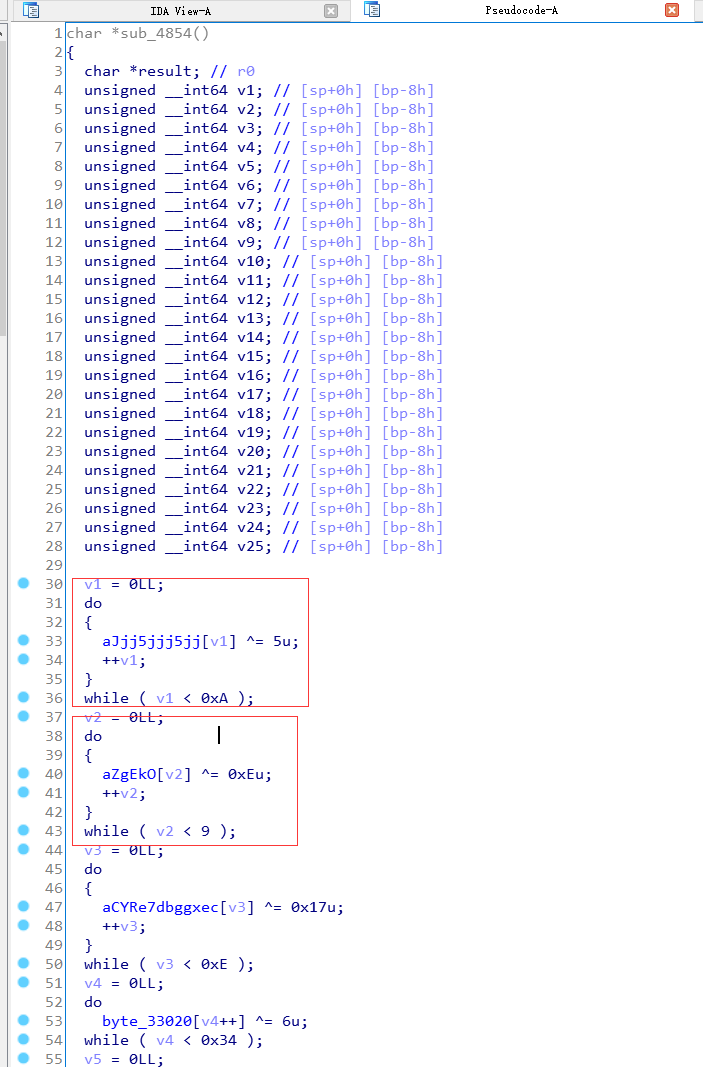
脚本处理有两种方式:
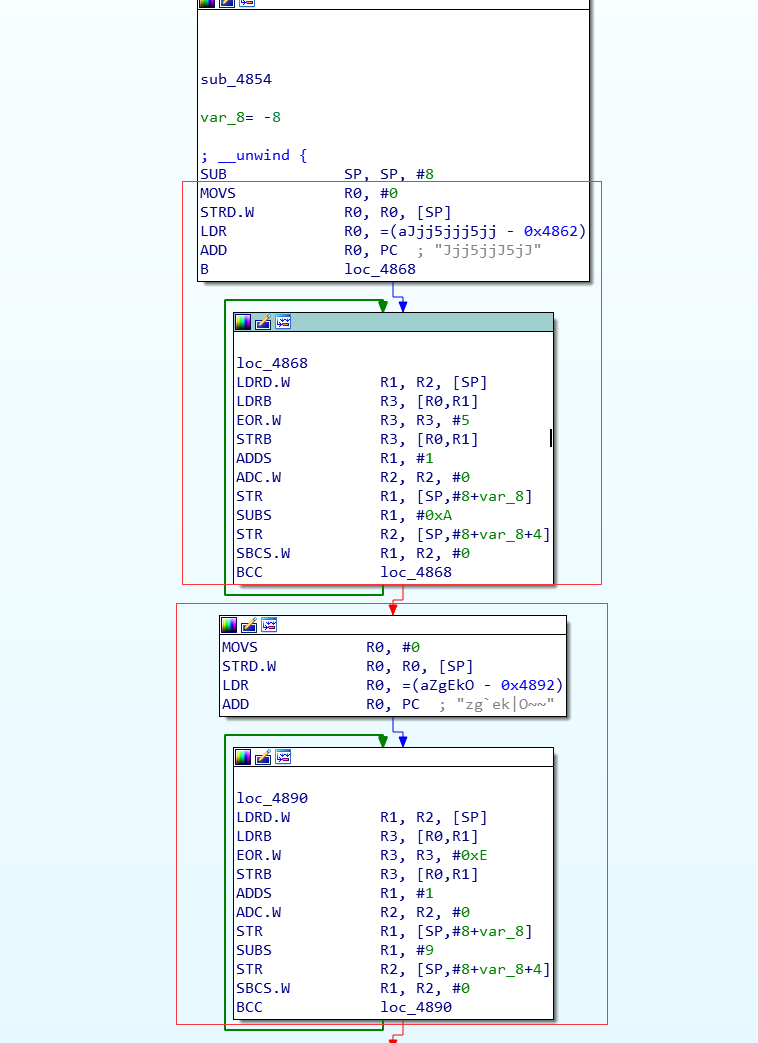


import idcdef find_next_chunk(addr):if not idc.is_code(idc.get_full_flags(addr)):return False, None, None, None, Noneop = idc.print_insn_mnem(addr)if op != 'MOVS' and op != 'MOV.W':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'STRD.W':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'LDR':return False, None, None, None, Nonearr_start = idc.get_wide_dword(idc.get_operand_value(addr, 1)) + addr + 2 * 3addr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'ADD':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op == 'B':addr = idc.get_operand_value(addr, 0)op = idc.print_insn_mnem(addr)if op != 'LDRD.W':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'LDRB':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'EOR.W':return False, None, None, None, Nonexor_ch = idc.get_operand_value(addr, 2)addr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'STRB':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'ADDS':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op == 'ADC.W':addr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'STR':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'SUBS':return False, None, None, None, Nonearr_len = idc.get_operand_value(addr, 1)addr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'STR':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'SBCS.W':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'BCC':return False, None, None, None, Nonenext_addr = idc.next_head(addr)return True, next_addr, xor_ch, arr_start, arr_lenelif op == 'STR':addr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'ADCS.W':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'STR':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'ADCS.W':return False, None, None, None, Noneaddr = idc.next_head(addr)op = idc.print_insn_mnem(addr)if op != 'BNE':return False, None, None, None, Nonenext_addr = idc.next_head(addr)return True, next_addr, xor_ch, arr_start, 1else:return False, None, None, None, Nonedef decode_arr(arr_start, arr_len, xor_ch):for addr in range(arr_start, arr_start + arr_len):ch = idc.get_wide_byte(addr)# print hex(ch)idc.patch_byte(addr, ch ^ xor_ch)idc.create_strlit(arr_start, arr_start + arr_len + 1)def proc_func(func_addr):if not func_addr:return# Thumb, func_start_addr+1==func_addrfunc_start_addr = idc.get_func_attr(func_addr, idc.FUNCATTR_START)func_end_addr = idc.get_func_attr(func_addr, idc.FUNCATTR_END)print hex(func_start_addr), '----->', hex(func_end_addr)addr = func_start_addrwhile addr < func_end_addr:succ, next_addr, xor_ch, arr_start, arr_len = find_next_chunk(addr)if succ:print hex(addr).ljust(10), hex(xor_ch).ljust(10), hex(arr_start).ljust(10), arr_lendecode_arr(arr_start, arr_len, xor_ch)addr = next_addrelse:print '*' * 10, hex(addr)addr = idc.next_head(addr)print '\n' * 3def decode_str():idc.auto_wait()start_addr = idc.get_segm_by_sel(idc.selector_by_name('.init_array'))end_addr = idc.get_segm_end(start_addr)addr = start_addrwhile addr + 4 <= end_addr:func_addr = idc.get_wide_dword(addr)proc_func(func_addr)addr += 4decode_str()


import unicornimport idcdef func_block_handle(uc, address, size, user_data):if address in (0, 0x29BC0):uc.emu_stop()def decode_str():idc.auto_wait()dir_path = r'/Users/lll19/Downloads/legu/'bin_len = idc.prev_addr(idc.BADADDR)bin_len = (bin_len / 0x1000 + (1 if bin_len % 0x1000 else 0)) * 0x1000bin_path = dir_path + 'elf_bin'idc.savefile(bin_path, 0, 0, bin_len)f_bin = open(bin_path, 'rb')bin_bytes = bytes(f_bin.read())f_bin.close()stack_size = 0x100000stack_top = bin_lenstack_bottom = stack_top + stack_sizeuc = unicorn.Uc(unicorn.UC_ARCH_ARM, unicorn.UC_MODE_THUMB)uc.hook_add(unicorn.UC_HOOK_BLOCK, func_block_handle)uc.mem_map(0, bin_len)uc.mem_write(0, bin_bytes)uc.mem_map(stack_top, stack_size)start_addr = idc.get_segm_by_sel(idc.selector_by_name('.init_array'))end_addr = idc.get_segm_end(start_addr)addr = start_addrwhile addr + 4 <= end_addr:func_addr = idc.get_wide_dword(addr)addr += 4if not func_addr:continueprint hex(func_addr)func_end_addr = idc.find_func_end(func_addr)uc.reg_write(unicorn.arm_const.UC_ARM_REG_SP, stack_bottom)uc.reg_write(unicorn.arm_const.UC_ARM_REG_LR, 0)uc.emu_start(func_addr, func_end_addr)f_save = open(bin_path, 'wb')f_save.write(str(uc.mem_read(0, bin_len)))f_save.close()idc.loadfile(bin_path, 0, 0, bin_len)decode_str()






1、执行0x2B604处的代码。读取tosversion文件的内容,处理后作为解密的key(该处只读取了16个字节,但是解密的时候,复制了32字节的key,但是不影响,实际执行解密的时候只用了前16字节)。
2、循环执行0x2B2AC处的代码。解压出所有被抽取指令的dex。
3、循环执行0x2315C、0x2B2AC、0x115F4这三处代码,分别对应class信息的解密、解压、建索引。
4、循环执行0x2315C、0x2B2AC这两处代码,分别对应指令的解密、解压。
5、遍历所有dex的hash表,循环执行0x101b8处的代码进行指令修复。
完整的脱壳脚本就不贴了,提示超出字数限制了,我把它放在附件里面了。
样本打包后附件大小也超限制了。
样本我放网盘了,附件只保留了脚本文件。

看雪ID:卧勒个槽
https://bbs.pediy.com/user-home-745332.htm

# 往期推荐
1.FartExt超进化之奇奇怪怪的新ROM工具MikRom
3.栈与栈帧的调试


球分享
球点赞
球在看

点击“阅读原文”,了解更多!
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注KnowSafe微信公众号
关注KnowSafe微信公众号随时掌握互联网精彩
- 热门AI工具OpenClaw出现高危安全漏洞 请立即升级到v2026.1.29+版
- 伊朗切断全国互联网和电话通信服务应对网络攻击 互联网流量跌至平时的3%
- WeClone从聊天记录创造数字分身的一站式解决方案
- WeWe RSS搭建公众号文章自动采集管理器
- 微擎面板(w7panel)反向代理功能全新上线 轻松搭建专属CDN服务!
- Apache Tomcat发布安全更新 借CVE-2024-56337可远程代码执行
- 太猖獗!近期勒索攻击事件频发,业内人士发表见解
- 骁龙嘉年华震撼来袭,开启夏日数字娱乐狂欢!
- 在看 | 北京健康宝遭受境外网络攻击
- 苹果 AR/VR 头显或售价 12000 元起,网友:“买来能干啥?”
- 云原生灰度更新实践
- 在看 | 一周网安回顾(2021.10.8-10.14)
赞助链接




