

出品 | AI科技大本营(ID:rgznai100)
你是否见过破巢而出的小狗?或者是在飞艇里俯瞰蒸汽朋克城市?又或是两个机器人在电影院里度过一个浪漫夜晚呢?这些听起来可能有些不可思议,但一种名为文本到图像生成的新型机器学习技术使它们成为可能。
这些模型可以通过简单的文本提示生成高质量的照片级真实感图像。在 Google 研究院科学家和工程师一直在探索使用各种 AI 技术进行文本到图像的生成。经过大量测试,最近宣布了两种新的文本到图像模型 - Imagen 和 Parti。两者都能够生成逼真的图像,但使用不同的方法。
使用文本到图像模型,人们提供文本描述,模型生成与描述尽可能匹配的图像。像“一个苹果”或“一只坐在沙发上的猫”这样简单的描述,也可以是更复杂的细节,互动和描述性指标,比如“一个可爱的树懒拿着一个小宝箱。胸口发出明亮的金色光芒。在过去几年中,ML 模型已经在具有相应文本描述的大型图像数据集上进行训练,从而产生了更高质量的图像和更广泛的描述。这引发了这一领域的重大突破,包括 Open AI 的 DALL-E 2。
谷歌亮出最新文本到图像生成模型
如今,文本到图像生成模式风靡一时,但谷歌公司最近密集的一系列新发布,却让大众有些出乎意料。5 月底谷歌刚刚推出 Imagen,它结合了 Transformer 语言模型和高保真扩散模型的强大功能,在文本到图像的合成中提供前所未有的逼真度和语言理解能力。与仅使用图像 - 文本数据进行模型训练的先前工作相比,Imagen 的关键突破在于“谷歌的研究者发现在纯文本语料库上预训练的大型 LM 的文本嵌入对文本到图像的合成显著有效。”Imagen 的文本到图像生成可谓天马行空,能生成多种奇幻却逼真的有趣图像。在 Imagen 发布之后,他们进行了新的研究,决定展示另一个模型构建来完成同样的任务。这一最新模型被命名为Parti(Pathways Autoregressive Text-to-Image)。虽然 Imagen 和 DALL· E2 是一种扩散模型,但 Parti 遵循 DALL· E 的足迹作为自回归模型。无论其架构和培训方法如何,最终用途都是一样的,这些模型(包括 Parti)将根据用户的文本输入生成细致的图像。Imagen 的图像生成具有与 Open AI 的DALL-E 2 相似的架构,但输入依据的是大型 AI 语言模型——由于具有更高的语言理解能力,因此可以从文本描述获得更好的图像生成结果。新的 AI 模型 Parti 尝试使用一种更接近大型语言模型功能的替代架构,这些语言模型能根据之前的单词和句子或段落的上下文预测合适的新词。Parti 将这一原则应用于图像,并取得了成功。Parti 表明,与大型语言模型一样,图像 AI 通过更全面的训练和更多的参数获得了明显更好的结果。它还可以将长而复杂的文本输入准确地翻译成图像,这表明它可以更好地理解语言和主题之间的关系。再来看下 Parti 效果,袋熊在瀑布旁,背着书包,拄着拐杖眺望着远方:
Parti 详细参数
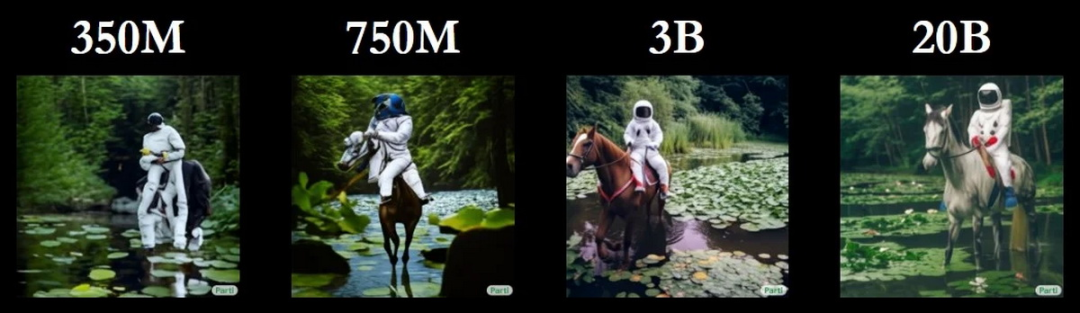
研究人员创建了四种不同规模的 Parti 模型,其中包括 3.5 亿、7.5 亿、30 亿和 200 亿的参数计数。这些模型是使用 Google Cloud TPU 进行训练的,这些 TPU 能够轻松支持创建这些巨大的模型。像所有其他文本到图像生成器一样,Parti 以各种类似的方式处理存在的各种问题,例如不正确的对象计数、混合特征、不正确的关系定位或大小、不正确处理否定,列表可能会继续等。
Parti 生成的图像分辨率为 256 x 256 像素,可以放大到 1024 x 1024 像素。下图显示了四种经过不同级别训练的 Parti 模型在相同命令提示下生成图像的质量差异。具有 200 亿参数的最大模型生成了与长文本输入匹配的无错误图像。最大版本的 Parti 模型甚至可以拼写单词,而 DALL-E 2 只能生成图像。谷歌的研究团队写道:“20B 模型特别适合于需要世界知识、特定视角或符号书写和表示的抽象任务。”另外,Parti 还可以生成超越培训材料及其主题的出色的图像。研究人员认为,这意味着图像 AI 能够准确地再现世界知识,以精细的细节和交互组合产生许多主角和对象,并遵循特定的图像格式和风格。
生成图像背后风险也令人担忧
尽管 Parti 已经有能力生成“以假乱真”的超逼真图片,但其实该系统存在的一些问题也不容忽视。 谷歌研究团队对模型生成的图像可能包含对人的刻板印象也感到担忧,这也是 Imagen 和 DALL-E 2 正在努力解决的问题。此外,由于可能会产生逼真的人物图像,因此存在额外的深度伪造风险。研究团队目前没有公布模型、代码和其他数据。谷歌也将推动结合两种模型的优点的新想法,并扩展到相关任务,例如添加通过文本交互式生成和编辑图像的功能。还将继续进行深入的比较和评估,以符合人工智能原则。研究者的目标是以安全、负责任的方式将基于这些模型的用户体验带给世界,从而激发创造力。https://blog.google/technology/research/how-ai-creates-photorealistic-images-from-text/https://wandb.ai/telidavies/ml-news/reports/Google-s-Parti-The-Newest-Text-To-Image-Generation-Model--VmlldzoyMjExNjA2

在线申请SSL证书行业最低 =>立即申请
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 关注KnowSafe微信公众号
关注KnowSafe微信公众号







