 近期,巨杉数据库举行线上发布会,发布基于「湖仓一体」架构的 v5.2 版本,提升多项「实时」能力,诠释公司「释放全量数据价值」的价值主张。深度解析在数字化时代下,SequoiaDB 如何围绕金融银行业的实时需求,全面提升结构化查询分析、非结构化存取、性能监控故障诊断及数据生命周期管理的四大能力,让全量数据的价值从「内部离线」向「实时对客」进一步释放。会中,赛迪咨询深度解读全国首个《湖仓一体技术研究报告》,详细介绍湖仓一体架构的兴起与未来发展方向。
近期,巨杉数据库举行线上发布会,发布基于「湖仓一体」架构的 v5.2 版本,提升多项「实时」能力,诠释公司「释放全量数据价值」的价值主张。深度解析在数字化时代下,SequoiaDB 如何围绕金融银行业的实时需求,全面提升结构化查询分析、非结构化存取、性能监控故障诊断及数据生命周期管理的四大能力,让全量数据的价值从「内部离线」向「实时对客」进一步释放。会中,赛迪咨询深度解读全国首个《湖仓一体技术研究报告》,详细介绍湖仓一体架构的兴起与未来发展方向。
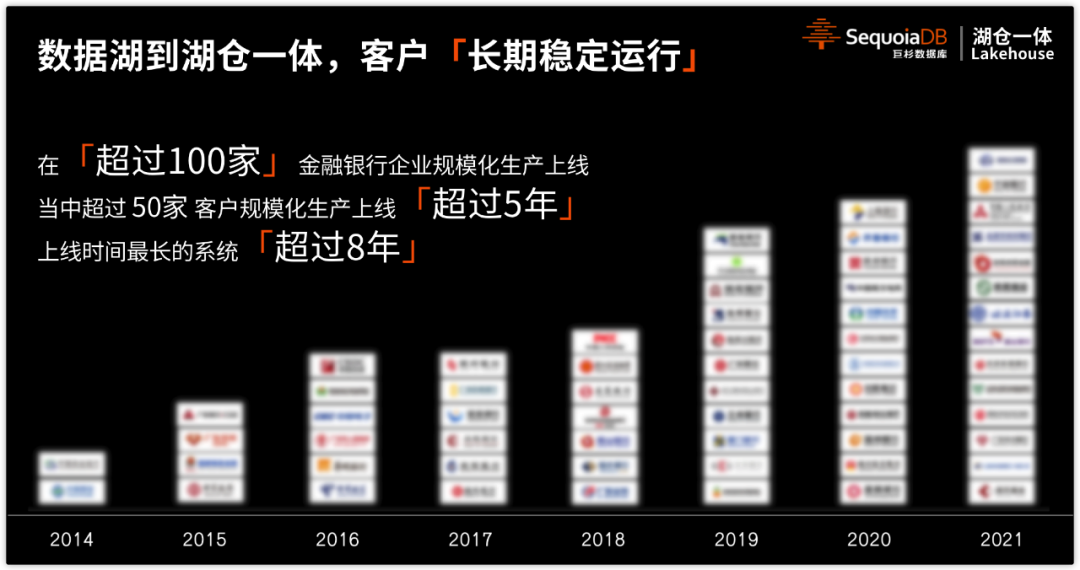
巨杉基于数据湖的实时能力已经达到全球领先,技术实力得到了金融头部客户的认可。2012 年巨杉数据库正式成立,并于 2014 年正式商用,产品已在超过 100 家金融银行客户规模化生产上线,其中不乏中国人保、民生银行、南方电网、中国太平保险等世界 500 强企业及广发银行、广东省农信、四川省农信、吉林省农信、恒丰银行、渤海银行、上海银行、上海农商银行、中国证券登记结算有限公司、海通证券等典型客户。在单一客户中 SequoiaDB 所支持的最大数据量,已经达到 1.4 万亿行、服务器规模超过 400 台、数据容量达数 PB;SequoiaDB 更服务于多个政府平台,如支持“粤省事”平台的医保、社保数据查询,这些数据也助力新冠核酸检测,帮助政府匹配核酸检测情况。
双核心:交易核心+数据核心,让全量数据实时可得
过去的 10 年,是信息化向数字化转型的 10 年,伴随数字化的深化发展,企业不但需要面向业务交易的信息化传统「交易核心」,同时更需要面向数据价值的「数据核心」。移动互联网、AI、IOT、大数据等的兴起与发展,数字化成为企业的全新课题,数据库是企业数字化转型的基石。信息化时代,「交易核心」解决的是交易系统的问题,面向渠道、产品、客户、核算及清算等业务流程,确保业务闭环。其交易过程产生的海量流水数据,将成为「数据核心」的生产要素。数字化时代,「数据核心」解决的是数据的采集、整理、聚合、运用等问题。数字化新核心将为信息化「交易核心」提供实时、跨业务的全量数据,以及基于数据的决策依据,实现数据价值的持续释放。「实时」是「释放全量数据价值」的关键。10 年前,巨杉数据库自萌芽之初就意识到,数据会成为社会发展关键的要素资源,需要提供面向全量数据的实时对客及高并发处理能力。业界遇到的普遍痛点是,面向「交易核心」的数据库因架构及技术限制仅能服务于指定的业务系统,且无法处理全量数据;以 Hadoop 为代表的大数据产品虽然可以存放全量数据,但无法提供实时处理能力,两者皆无法满足全量数据实时对客服务的发展需求。因此巨杉毅然开始了自研原生分布式数据库内核的道路,从「多模数据湖」、「实时数据湖」发展到「湖仓一体」,为客户提供「数据核心」所需的全量数据存储,实时对客服务,及基于统一数据源的分析能力,充分激活客户的离线数据。 
四大实时能力提升,SequoiaDB v5.2 释放全量数据价值
巨杉数据库基于湖仓一体架构的 SequoiaDB v5.2 版本进行了多项更新,此次发布会主要介绍了四大实时特性的能力提升。即将发布的 SequoiaDB v5.2 版本让全量数据的价值从「内部离线」向「实时对客」进一步释放。查询更实时,所有数据可毫秒级访问。面向结构化数据,SequoiaDB v5.2 版本提供深度的 Join 优化及列存微分区技术,在多个查询场景下,性能达到了毫秒级实时返回;分析场景中,性能更获得了 10 倍以上提升,让数据湖的查询分析更实时。存取更实时,吞吐量提升 30% 以上。面向非结构化数据,巨杉通过「分片并发」及「可变分区大小」的技术,相比原有版本,SequoiaDB v5.2 版本吞吐量提升 30% 以上,让数据湖的非结构化数据存取更实时。诊断更实时,业务问题分钟级定位。发布会上,巨杉数据库发布 SAC 运维管理工具的重要特性更新,运行监控方面提供了全 GUI 的性能及故障分析能力,SAC 基于分布式架构的实时诊断,可实现业务问题分钟级定位。全量数据生命周期管理,提升人效及能效。部署架构方面,支持多配置硬件的混合部署,针对高并发数据与低并发数据,做到按需调度;面向横跨结构化、非结构化数据,提供一体化的开发及管理能力,提升人效及能效,在成本可控的前提下,实现全量数据实时可用。
技术迭代互补,而非替代
巨杉数据库深耕第三代分布式数据库技术,我们认为分布式数据库的星辰大海,绝不仅限于对交易核心数据库的替代。SequoiaDB 的「湖仓一体」是从「多模数据湖」、「实时数据湖」结合「实时数仓」发展而来,为客户提供「数据核心」所需的全量数据存储,实时对客服务,及基于统一数据源的分析能力,充分激活客户的离线数据。SequoiaDB 正通过湖仓一体架构提供面向多模、实时、分析的需求,与各类集中式及分布式交易核心数据库成为上下游合作伙伴,驱动数字化业务创新,释放全量数据价值。
60 年前诞生的第一代数据湖,以网格型、层次型数据库为代表,至今还有不少企业依然在使用;第二代数据库,以处理交易核心业务的关系型数据库为代表,是当前业界的主流。第一、第二代数据库大都基于集中式架构,因架构、数据结构的限制,导致大量的数据产生后,无法对业务流水、用户过程数据等全量数据做保存沉淀。往往需要将全量数据异步导出到大数据等后端平台,无法提供给终端用户实时查询分析,成为了仅对内部使用的离线数据,难以满足终端用户实时查询需求。巨杉数据库 SequoiaDB 通过基于「湖仓一体」架构,支撑企业的「数据核心」。从企业多个「交易核心」数据库所产生的业务流水数据,可以以流式入湖的方式,秒级汇聚到 SequoiaDB 形成全量数据底座。实时数据湖:为不同业务的跨系统查询,或多年流水数据获取,提供高并发的实时查询能力,所有数据实时可得。相比原来跨多系统进行数据异构访问的方式,SequoiaDB 协助客户将业务响应时间从分钟、小时级延迟,到秒级延迟的改变,让用户满意度获得大幅提升。多模数据湖:为影像系统、远程银行等需要大量管理非结构化数据的系统,提供多模数据湖技术重点优化非结构化对象数据的高并发实时存取能力,实现跨多数据类型的一体化管理,提升研发及运维的“人效”。实时数仓:在数据湖内提供高性能分析引擎,可以协助企业基于准确而且统一的数据源,进行数据的实时探索及分析、统计、加工,降低数据再次流动的开销,提升数据处理“能效”,构建绿色低碳的数据基础设施。 
培育数据沃土,打造产学研生态链
数据库的发展不但需要技术的创新迭代,同时也需要建立良好的技术生态。凭借南沙“立足湾区、协同港澳、面向世界”的发展定位,在过去的一年间,巨杉数据库积极打造产学研生态链。通过分布式人才培养、高校协同、上下游企业赋能等,携手客户、合作伙伴、高校共同推进分布式技术的发展。目前,通过巨杉数据库培训认证的技术工程师已经超过一万人。在高校协同方面,巨杉数据库先后在华南理工大学、深圳大学设立长期的「巨杉数据库奖学金」,推动中国分布式数据库人才培育。在产业生态方面,巨杉积极推动行业标准、团标及生态联盟的建设,致力于建设一个开放的基础软硬件企业级生态,特别是已经与鲲鹏、飞腾、海光、麒麟、统信等厂商的 150 多款信创上下游产品完成互认证。发布会上,赛迪咨询也对全国首篇《湖仓一体技术研究报告》进行深度解读,将湖仓一体技术定义为未来发展趋势。未来,巨杉数据库 SequoiaDB 也将持续聚焦于分布式特性,通过「湖仓一体」架构为客户打造「数据核心数据库」,成为数字化时代下坚实的数据基础设施。在“信创”产业中,坚持践行信息技术应用创新的理念,服务于企业全量数据实时业务场景,与各类集中式及分布式交易核心数据库成为上下游合作伙伴,驱动数字化的业务的创新发展,释放全量数据价值。
在线申请SSL证书行业最低 =>立即申请
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 关注KnowSafe微信公众号
关注KnowSafe微信公众号







