
作者 | 郭人通
“从用 Python 定义流水线,到生成 Docker 镜像,再到启动服务并调用执行,一共不到 30 行代码!?”- 模型推理搞的飞快之后,发现预处理、后处理才是瓶颈。
- 除了需要搜寻各种英伟达的算法库,还需要学习各种高性能计算和 CUDA 编程技术,对着图片解码、视频解码、tensor transform、分词之类的操作一顿猛搞。
- 不仅要写一堆脚本程序,努力的把一整条处理流水线串起来,更要设计好服务的调用接口。
- 串完发现流水线各级速度不匹配,想着把慢的阶段起多实例并行,又扯上了负载均衡和流水线优化。
- 一切内容终于准备就绪了,竟然又要去学写 Dockerfile ......
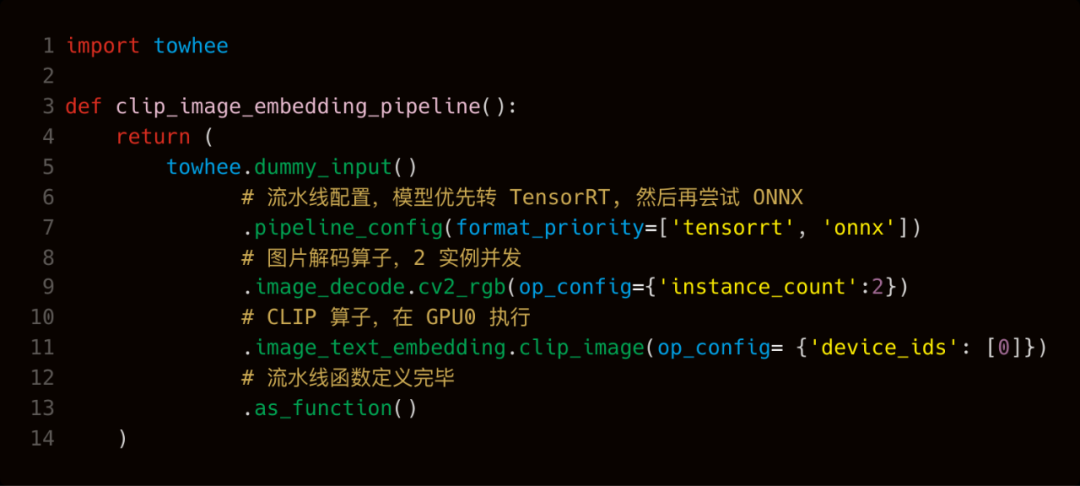
为了解决上面一连串的问题,我们发起了一个开源项目 Towhee,任何用户都能够从 Python 代码一键构建面向生产的高性能推理流水线。这个项目提供了一套优雅的函数式 Python 编程接口,以及一组覆盖日常工作所需要的工具集,只需要几行代码,就能够自动的解决上述问题:将推理流水线内出现的代码(模型、算法、数据处理过程等)转换成对应的高性能实现,组织端到端的推理服务代码,一键生成 Docker 镜像。下面举一个小例子演示如何使用 Towhee:用 CLIP 做图片 embedding 特征提取。从定义流水线到生成 Docker 镜像,再到启动服务并调用执行,一共不到 30 行代码。流水线接受图片作为输入,输出图片对应的 embedding 向量。这个流水线包含两个算子 image_decode.cv2_rgb 和 image_text_embedding.clip_image,分别负责图片的解码以及 CLIP 的图片特征提取。例子里对流水线进行了配置,通过 pipeline_config 的 format_priority 参数给到 Towhee 一个提示,告诉 Towhee 优先把模型转到 TensorRT 的格式去做推理,如果失败就尝试走 ONNX。image_decode.cv2_rgb 的算子配置是 num_instance=4,让 Towhee 在流水线中起4个图片解码的实例提高并发。image_text_embedding.clip_image 的算子配置是 dev_id=0,让 Towhee 在 GPU0 上跑 CLIP 的推理。如果指定了使用 GPU 进行模型推理,Towhee 会自动的选择 GPU 版本的模型前后处理过程,并在同一块 GPU 设备上执行前处理、模型推理、后处理。更多流水线配置能力详见官方文档(https://docs.towhee.io/)。接下来,我们通过 Towhee 把这个流水线制作成 Docker 镜像,这里选用 Nvidia Triton 作为高性能推理服务框架:命令执行完毕,我们将得到一个名为 clip_image_embedding:v1 的镜像,使用下面的命令启动服务实例:在完成了模型服务启动之后,我们在本地编写一个简单的测试程序,通过调用刚才启动的服务,对当前目录下 jpg 图片做 embedding 特征提取:如果你想进一步做一个基于 CLIP 的 “文本-图像跨模态” 召回服务,我们还可以再添加一个用 “CLIP 提取文本 embedding 特征” 的流水线,并进一步丰富服务的调用代码,完整程序不会超过 100 行 Python 代码。(这里因为和上面的示例代码比较接近,就不展开赘述了,感兴趣的同学可以自行尝试,遇到问题欢迎到 Slack 或微信反馈,链接见文章末尾)除了对大量工程细节的极致封装,Towhee 在性能方面也有不俗的表现。在我自己的机器上(64核CPU,3080单卡),使用 HuggingFace 的 CLIP 预训练模型和配套工具库实现了同样功能的流水线,并和 Towhee 的流水线进行了性能对比:
HuggingFace 与 Towhee 的流水线性能对比经过多次实验,HuggingFace 流水线的平均 QPS 67,Towhee 流水线的平均 QPS 328。Towhee 的流水线有接近 5 倍的提速。也就是说,通过使用 Towhee,仅用一块卡就可以达到之前五块卡的服务能力,两个字,省钱!接下来,继续分享一些 Towhee 中的重要组件和实用工具:Towhee Operator Hub、DataCollection 编程接口、高性能推理服务,以及项目的 Roadmap。Towhee 的 Hub 不叫 Model Hub,而是叫 Operator Hub。主要原因在于,Towhee 是面向端到端的流水线构建,不仅仅是聚焦神经网络模型,还更加关注算法模块功能的丰富度、高性能推理、标准的任务接口。算法模块的丰富度:Towhee 中的算法模块,包括神经网络模型,也包括各种五花八门的数据处理方法,如音视频编解码、图片裁切、文本分词、向量降维、数据库操作等。- Paper with Code 关键领域的 benchmark 上榜模型;
目前,Towhee 已经覆盖计算机视觉、自然语言处理、音频、生物医药、多模态五大领域的十多项任务,120多种模型结构,700多个预训练模型。查看 Towhee 支持的 Operator 列表(https://github.com/towhee-io/towhee)。高性能推理:Towhee Hub 上的算法模块除了提供预训练模型以及Fine-tuning 能力,会更加聚焦流水线落地后的推理性能。Towhee 会为常用算法或前沿模型提供对应的高性能实现,根据 Python 侧流水线的定义,在推理服务的构建期进行自动化替换。这些加速支持包括:- 常见的数据处理过程加速,如图片、音频、视频解码加速等。
标准的任务接口:Towhee 会按照任务类型对算子进行模块化组织。任务类型确定了标准的调用接口,并通过算子提供这些接口的不同实现。在 Towhee Hub 中 Operator 的组织方式类似 PapersWithCode,相同任务的 Operator 会组织在一个分类下,结构目录清晰、方便阅读和使用。目前,Towhee 社区也在尝试逐步覆盖 Papers with Code 上的重点任务,支持用户对 SOTA 模型的快速试用,避免用户在 “读懂论文-看懂论文作者的初版实现-面向工程落地的代码重构-PoC-性能优化” 这个链条上的重复造轮子。Towhee 会对已支持的模型添加 Papers with Code 链接。如果在 Papers with Code 模型页面的 'Code' 部分看到 towhee-io/towhee,就说明在 Towhee 可以对该模型进行试用。例如跨模态视频召回的 CLIP4Clip 模型。Towhee Hub 上的每一个 Operator repo,既是一个模型的代码仓库,也是一个直接可调用的模块。如前面的例子中用到的 image_text_embedding.clip_image 算子,对应 Hub 上 image-text-embedding/clip_image 这个 repo。这个仓库的用户名和仓库名分别与流水线调用中的包名 image_text_embedding、算子名 clip_image 对应。Towhee 规定了一套 Operator 代码仓库的接口协议。只要代码仓库的组织方式遵守这套协议规范,就可以通过 Towhee 提供的工具,将仓库代码自动化打包,并可以通过 "用户名.仓库名" 的方式对算法模块直接加载调用。任务接口标准化有一个非常大的优势是可以灵活切换模型,而不用担心引入额外的工程量。这对于快速 PoC 以及流水线升级都很重要。在原型阶段,可以根据业务逻辑确定需要哪些类型的任务,由于相同任务下的不同算子具有一致的调用接口,因此可以乐高积木式的自由组合,进行快速的效果尝试。在生产环境如果需要对流水线的某个 Operator 升级,也只需要在流水线的定义中替换相应的 Operator,通过 Towhee 重新构建 docker image 即可。目前 Towhee 社区也在收集用户的算子需求,在每个版本中进行汇总并更新实现。有这方面需求的同学可以加项目的Slack/微信群进行讨论或提 github issue。相关链接在文章末尾。Operator 是乐高积木,DataCollection 接口则是强力胶,用来连接积木。通过 DataCollecton 接口,Towhee 用户可以轻松构建推理流水线。DataCollection 在逻辑上的定义是一个带 Schema 的非结构化数据表格,每一行对应一个数据实体(Entity),每一列对应一种数据属性。一个流水线对应着一组数据属性操作,每个 Operator 接受一到多个数据属性作为输入,并产生新的数据属性作为输出。- 作为 driver program 连通业务逻辑与流水线服务。
在文章一开始 CLIP 的例子中,已经简单演示了后两个用法。这里对流水线的本地快速原型构建做一个简单的介绍。CLIP 这个例子的本地可执行版本写出来是这样:代码中方括号的部分指定了 schema 的相关信息。这个例子中 3 个 Operator 够成了一个收尾相连的链,当然,还可以通过 DataCollection 定义一些比 operator-chain 更复杂的 DAG:这个例子中,我们先通过 YOLO v5 检测图片中出现的 objects,然后在原图中将这些 objects 裁切出来,并使用 CLIP 分别对这些 objects 的图片进行 embedding feature 的提取。这个 DAG 画出来是这个样子:
Towhee 项目的目标不是打造一款全新的推理引擎,而是聚焦于让现有的高性能推理引擎更加落地。目前,Towhee 的推理服务适配了 Nvidia Triton 推理框架,主要特性包括:- 推理流水线 DAG。相比常见的推理引擎只支持 “单纯的神经网络模型推理”,或 “前处理-模型推理-后处理 三阶段流水线”,DAG 型的流水线可以覆盖更丰富的数据处理组合逻辑。
- 异构的推理后端。DAG 中的每一个算子节点可以在不同的后端引擎上执行,既包括神经网络推理引擎,如 Pytorch(TorchScript),ONNXRuntime, TensorRT;也包括通用的数据处理过程,如 Python 函数,DALI,或自定义Python/C++后端;还包括数据库/索引连接器,如 Milvus,FAISS。
- 极致的推理性能。推理服务可在 NVIDIA GPU,x86/ARM CPU 上高效运行,支持多 GPU,支持多模型实例,支持实时、流式、批处理、动态批处理请求,支持流水线自动并行。
- Docker 与 Kubernetes 部署。推理流水线都以 Docker 镜像的方式进行封装,对外提供 grpc 与 http 接口,隐藏大量内部复杂性。可通过 Kubernetes 轻松部署推理微服务。
在支持上述特性的同时,Towhee 为用户完成了大量自动化工作,包括逻辑图到物理图的映射,物理图到异构执行后端的映射,以及运行期调度。
上图给出了 CLIP 这个例子从流水线定义到生成推理流水线服务的过程。从上到下,整个自动化构建与执行过程共分三个阶段,分别是逻辑图(编译期),物理图(编译期),以及执行后端(运行期)。逻辑图是通过对 DataCollection 进行 Trace 所获得的关于图定义的完整元信息。物理图会对逻辑图中各个算子节点进行物理实现的绑定,如
image_decode 节点在物理层会以 Python model 的方式执行 OpenCV 程序,CLIP
对应的图片前处理过程在物理层会绑定 DALI 实现,CLIP 模型在物理层会绑定 TensorRT 实现。同时,这些算子节点会在物理层完成 ensemble 的相关配置、实例个数配置、以及物理资源的分配。在运行期,会根据物理图上各个节点的物理绑定,适配执行后端,以及物理内存与计算资源,并根据图上各个算子节点的依赖关系,驱动流水线的自动化执行。Towhee 项目的 Roadmap 可以在官网(https://towhee.io/)查看。目前,Towhee 项目还在快速迭代与重度研发的阶段。项目 Roadmap 上的关键内容有:模型方面,近期会聚焦 CVPR 2022 新出炉的前沿成果,如 CV 大神何恺明的 MAE,香港大学、UC Berkeley、腾讯合作的 MCQ 等。同时,会集成 AutoEncoder ,提供向量降维能力。对于中文跨模态搜索、多模态召回、代码等数据上的任务类型也会有模型更新。进展详情请关注项目的 Model ChangeLog。- MAE:Masked Autoencoders Are Scalable Vision Learners CVPR2022 (backbone)
- SVT:Self-supervised Video Transformer (action recognition)
- TransRAC:Encoding Multi-scale Temporal Correlation with Transformers for
Repetitive Action Counting (repetitive action counting)
- CoFormer:Collaborative Transformers for Grounded Situation Recognition (action recognition/grounded action counting)
- MCQ:Bridging Video-text Retrieval with Multiple Choice Question (text video retrieval)
- STRM:Spatio-temporal Relation Modeling for Few-shot Action Recognition (action recognition)
- CoOp:Conditional Prompt Learning for Vision-Language Models (visual language task)
- CVNet:Correlation Verification for Image Retrieval (image retrieval)
- CodeBERT:A Pre-Trained Model for Programming and Natural Languages
- CodeGen:A Conversational Paradigm for Program Synthesis
- 更加统一的 DataCollection 批处理接口与流处理接口。
- 支持自定义的算子。Towhee 目前给出了比较丰富的标准算子模块,但在常见的业务流程中,通常会引入业务逻辑,自定义算子可以很好的满足这部分需求。Towhee 的自定义算子将会包含两种形态,一种是通过 python 的 lambda 表达式生成,另一种是通过继承 Operator 基类生成。
- 算子的打包与安装工具升级。支持基于 pip 的打包与安装,并提供基于 AWS S3 的模型参数下载服务,优化本地模型参数缓存。
- 支持视频与音频的推理流水线。长视频或长音频的处理往往会耗费大量物理资源,针对这类场景,Towhee 将不再一次性展开帧数据,而是提供流式的帧数据处理,以降低内存/显存需求。
- 基于 numba 的 python 算子自动优化 (实验阶段)。Towhee 通过自定义算子支持业务相关的逻辑,我们鼓励用户使用 python 来快速构建这些逻辑,同时,Towhee 会在底层对这些 python 代码进行尽可能的优化:基于 numba,使用LLVM编译技术解释字节码,优化 IR 并翻译到目标代码进行执行。
- 支持基于 Apache Arrow 的列存数据,提高本地内存利用率,支持连续内存上的向量化执行。
- Transformer 模型结构的执行性能优化(实验阶段)。
- https://github.com/towhee-io/towhee
- https://towhee.io/tasks/operator
 Towhee 团队 2023 秋季招聘已经启动
Towhee 团队 2023 秋季招聘已经启动
在线申请SSL证书行业最低 =>立即申请
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/














 关注KnowSafe微信公众号
关注KnowSafe微信公众号



