
出品 | AI科技大本营
“Generative AI(生成式AI)有什么社会价值?”当腾讯研究院的研究员将上面这个问题输入到ChatGPT中,得到如下回复:"生成式AI是一种人工智能技术,它可以使用训练数据来生成新的内容。这种技术可以用来解决各种问题,具有很高的社会价值。例如,它可以用来生成文本、图像、音频和视频,这些内容可以用来帮助人们了解世界,也可以用来提高工作效率。此外,生成式AI还可以用来解决一些非常复杂的问题,比如提供新的医疗方案、帮助制定更有效的政策、或者甚至帮助人类更好地了解自己。总的来说,生成式AI为人类提供了很多有价值的机会,有助于人类更好地理解世界,并创造出更多的价值。”在以上ChatGPT的四段回答中,首先给出了定义(是什么和做什么),然后说明为什么要使用它,包括举例和和强调重要性。最后,还进行了价值理念的归纳和升华。实话说,如果我们问一个对AI有所了解的人类,很大可能也回答不出这样内容完备和逻辑条理的答案,或许这就是以ChatGPT等为代表的生成式AI之所以震撼业界的原因。
不过,人工智能自诞生的七八十年来,带给人们的惊叹多了去了。从早期研究积木世界到最早的智能机器人Shakey,再到上世纪八十年代深蓝战胜国际象棋冠军卡斯帕罗夫,直至最近几年的AlphaGo战胜世界围棋冠军,人形机器人Atlas的后空翻和机器狗Spot的连滚翻……AI技术从来不缺让人震撼的元素,但真正能够产业化落地的却少之又少。正因如此,谷歌这些年也收敛了败家烧模式,开始讲起Responsible
AI的故事。相较谷歌,OpenAI是一家小公司,不过背后却有世界首富马斯克和巨头微软的背书。从2016年6月宣布以制造通用机器人和使用自然语言的聊天机器人作为公司发展目标后,便开始了GPT语言模型的研究。不过,真正让OpenAI火出圈的是在2021年推出的DALL-E,加上后来Stable
Diffusion的开源,文生图率先掀起了AIGC的热浪,伴随而来的是大语言模型ChatGPT火爆全网。尽管业界原本的期待是进化版模型GPT-4,但GPT-3衍生而来的ChatGPT还是给到人们不少意外之喜。除了如前文所示的对答如流,在检查程序代码上也丝毫不含糊。那么,以DALL-E、ChatGPT等为代表的生成式大模型真能掀起人工智能的产业革命吗?如果是历经了人工智能各流派兴衰的产业界老人,可能多少会持有怀疑的态度。但对于后生代的巨头科技企业和新时代的AI开发者来说,将会抱持更大的期待。当然,愿望虽好,AIGC能否真正完成变革,还需要从技术工程化、产业生态化,以及机遇和挑战等方面来进行多维度分析。腾讯研究院在近日发布了《AIGC 发展趋势报告 2023》(以下简称《报告》),对AIGC的发展趋势进行了深度解读。
ChatGPT、DALL-E、Stable Diffusion们如此牛X,它们的背后有哪些技术?生成算法并非新技术,2014年由伊恩•古德费洛最早提出生成对抗网络(Generative
Adversarial Network,GAN
)是最早的生成式模型。之后,进一步出现了Transformer、Diffusion等深度学习生成算法,下表为生成式算法的演进时间轴。可以说,AIGC背后的三个最重要的算法模型就是GAN、Transformer和Diffusion。GAN的重要性体现在最早推出,衍生了许多流行架构和变种,还有大量科学家和研究人员在使用这一模型。Transformer则是因为应用领域的广阔,包括NLP、CV
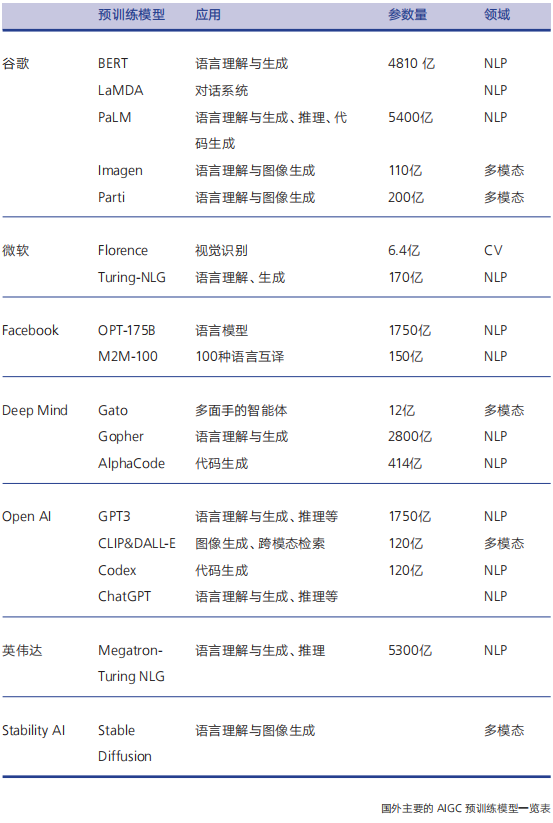
等领域的应用。后来出现的BERT、GPT-3、LaMDA等预训练模型都是基于Transformer模型建立的。Diffusion则因为最优化模型性能的表现,包括灵活的模型架构和精确的对数似然计算,让其成为最先进的图像生成模型。在《报告》中,是这样形容预训练的重要性的:预训练模型引发了 AIGC技术能力的质变。之所以称为“质变”,正因此后基于大量数据训练、拥有巨量参数成为AIGC实现多任务、多语言、多方式的核心驱动力。预训练开始的标志性事件是谷歌在2018年发布基于Transformer的机器学习方法BERT,自此AI进入大炼模型参数的预训练时代。由谷歌掀起的这场预训练旋风也拉起了一帮AI巨头和独角兽们的热情参与,下表是主要的AIGC预训练模型。除了生成算法和预训练,AIGC
要达成工程化也少不了多模态。在这点上,CLIP的重要性就体现出来了。2021年,OpenAI团队将跨模态深度学习模型
CLIP进行了开源,能够将文字和图像进行关联。这样一来,就从早期的单NLP、CV模型,扩展到语言文字、图形图像、音视频等多模态、跨模态模型。
生成算法、预训练模型、多模态让AIGC实现工程化,但一项技术能否真正撬动市场,还需要看它能否产业化。在如何构建产业化上,《报告》给出的结论是:AIGC产业生态加速形成和发展,走向模型即服务(MaaS)的未来。这些年来,SaaS(软件即服务)、PaaS(平台即服务)和IaaS(基础设施即服务)我们听了很多,当模型也变成一种服务之后,AIGC的产业未来会呈现出怎样的形态?如上图所示,从左到右依次是基础层、中间层和应用层。
首先,在产业的底层架构上,需要有以预训练模型为基础搭建的AIGC技术基础设施。和其他所有技术一样,基础层是最考验技术发展程度和可投入成本的地方,具有较高的进入门槛。据Alchemy
API创始人Elliot
Turner推测,训练GPT-3的成本可能接近1200万美元。所以,能够进入到这一层的企业主要是头部科技企业和科研机构。除了背靠微软不差钱的OpenAI,Stability.ai能够成为基础设施型公司也在于不断有资金注入,就在三个月之前,这家公司又获得了1.01亿美元的融资。基础设施的获利方式主要是通过受控的api调用进行收费,或者以开源为主,然后通过开发和销售专业版和定制版实现商业获利。中间层主要是垂直化、场景化、个性化的模型和应用工具。基础层的作用体现在提供通用模型训练平台,中间层的作用则是从通用调试和训练中快速抽取生成场景化、定制化、个性化的小模型和应用工具,这一层的目的在于实现不同行业、垂直领域、功能场景的工业流水线式部署。事实上,目前已经有不少团队开始基于AIGC的基础平台进行二次开发,比如二次元画风生成器Novel-AI,以及小冰公司通过AIGC生成动画短片。相较通用的AIGC生成器,经过中间层的加工之后,产出的内容产品可以直接提供给终端用户。基础层和中间层的应用主要面向B端,到了应用层就直接面向C端了。在这一层上,可以直接生成文字、图片和音视频。不过,相较于B端有更加功能强大的显卡,C端个人用户能否生成高质量的内容很考验消费级显卡的算力。英伟达、AMD、台积电等芯片制造厂商对这个领域的蛋糕也都在虎视眈眈。
机遇与挑战:引领AI 2.0变革,仍不能忽视知识产权、伦理等因素除了技术工程化和产业生态化,衡量AIGC未来发展还需要把控两大方面:机遇和挑战,即当前和潜在的有利及不利因素。
从机遇来看,可以说是非常得多。在《报告》中,从消费端:AIGC牵引数字内容领域的全新变革;到产业端:合成数据牵引人工智能的未来;再到社会端:合成数据牵引人工智能的未来。可以说从人们的生产生活,到社会组织的方方面面都可以有AIGC的参与。- AIGC正越来越多地参与到数字内容的创意性生成工作,以人机协同的方式释放价值,成为未来互联网的内容生产基础设施;
- AIGC带来的内容生产方式变革开始引起内容消费模式的变化,未来应用生态和消费市场将走向多样化;
- 在互联网迈向“在场(3D)”的趋势下,AIGC为3D互联网可以带来包括3D模型、场景、角色制作能效的提升,为创作者激发新的灵感;
Epic使用虚幻5引擎和程序化生成技术高效制作
《黑客帝国:觉醒》中的庞大城市(图片来源:知乎用户@王程)
- 未来随着性能的进一步提升,对话式AIGC在搜索、知识传播等领域有很大的应用空间。聊天机器人和数字人将成为新的、更具包容性的用户交互界面,不断拓展应用领域;
- 未来元宇宙的大型虚拟空间建设也离不开AIGC的参与,包括核心基础设施技术、数字原生内容的开发等等,通过AIGC可以释放大量包括开发者在内的人力和物力。
- 目前人工智能仍然处在发展的1.0阶段(AI 1.0),从AI 1.0走向AI 2.0,数据是最大的掣肘。从真实数据向合成数据的转化,可以推动人工智能迈向 2.0。而AIGC技术的持续创新,让合成数据迎来新的发展契机。
- 《报告》将AIGC对社会价值的推动概括为:AIGC的社会价值体现为革新数字内容与艺术创造领域,并将辐射到其他领域和行业,孕育新的技术形态与价值模式,甚至会成为通往AGI(通用AI)的可能性路径。
当然,有机遇就会有挑战。未来,AIGC也将面临包括知识产权、安全问题、伦理道德、环境保护等多个方面的挑战。
在吴恩达给DeeplearningAI的最新来信中,他表示到:“一个人需要几十辈子的时间,除了阅读什么都不做,才能获得GPT-3在训练过程中接触的单词数量。但是,网络聚合了为数十亿人编写或由数十亿人编写的文本,计算机可以随时访问其中的大部分内容。通过这些数据,LLMs获取了关于人类体验的丰富知识。尽管LLMs从未见过日出,但它已经阅读了足够多关于日出的文字,足以令人信服地描述日出的样子。因此,即使语言只是人类经验的一小部分,LLMs也能够接触到关于世界的大量信息。这表明,建立智能有多种途径,遵循生物进化或人类儿童成长的方式可能不是工程系统最有效的途径。”由此,他得出了当下机器学习算法获得智能的最有效途径——通过语言进化。而谷歌联合创始人,现实版的托尼·史塔克曾说过:“终有一天,世界上所有的知识都可以直接与我们的大脑连接。”从AIGC掀起的语言进化,到世界上所有的知识经验与我们的大脑相连究竟还有多远?你认为呢?
https://mp.weixin.qq.com/s/DBLJ2m98LHEo6VDgaN_kbQ 《吴恩达来信:靠语言进化的LLMs》
《2022-2023 中国开发者大调查》重磅启动,欢迎扫描下方二维码,参与问卷调研,更有 iPad 等精美大礼等你拿!

延伸阅读
-
Lobe Chat是一个开源的、可完全自托管的AI聊天平台,它完全打通了各种模型接入的壁垒,让你能用上市面上几乎所有主流大模型。包括Claude、ChatGPT、Gemini等等,甚至还能接入本地模型
-
微软在Windows 11的记事本中不断加入新功能,如Markdown(文本格式化)支持,但部分Windows 11用户对此并不买账,认为记事本原本以简洁著称,而新功能的加入破坏了这种简洁性。Wind
-
在 BreachForums (转世版) 黑客论坛中,有使用俄语的黑客自称已窃取高达 200 万个 OpenAI 账户的访问凭证,这名黑客还按行业规矩向潜在买家提供包含电子邮件地址和密码的样本数据。不
在线申请SSL证书行业最低 =>立即申请
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/





 关注KnowSafe微信公众号
关注KnowSafe微信公众号



