国内首个网络安全大模型评测平台 SecBench 发布





一是积累行业独有的网络安全评测数据集。评测数据是评测基准建设的基础,也是大模型能力评测最关键的部分。目前行业内还没有专门针对大模型在网络安全垂类领域的评测基准/框架,主要原因也是由于评测收据缺失的问题。因此,构建网络安全大模型评测基准的首要目标是积累行业内独有的网络安全评测数据集,覆盖多语言、多题型、多能力、多领域,以全面地评测大模型安全能力。 二是搭建方便快捷的网络安全大模型评测框架。“百模大战”下,大模型的形态各异,有HuggingFace上不断涌现的开源大模型,有类似GPT-4、腾讯混元、文心一言等大模型API服务,以及自研本地部署的大模型。评测框架如何支持各类大模型的快速接入、快速评测也很关键。此外,评测数据的多样性也挑战着评测框架的灵活性,例如,选择题和问答题往往需要不同的prompt和评估指标,如何快速对比few shot和zero shot的差异。因此,需要搭建方便快捷的网络安全大模型评测框架,以支持不同模型、不同数据、不同评测指标的灵活接入、快速评测。 三是输出全面、清晰的评测结果。网络安全大模型研发的不同阶段其实对评测的需求不同。例如,在研发初期进行基座模型选型阶段,通常只需要了解各类基座模型的能力排名、对比不同模型能力差异;而在网络安全大模型研发阶段,就需要了解每次迭代模型能力的变化,仔细分析评估结果等。因此,网络大模型评测需要输出全面、清晰的评测结果,如评测榜单、能力对比、中间结果等,以支持不同研发阶段的需求。

数据接入:在数据接入上,SecBench支持多类型数据接入,如选择题、判断题、问答题等,同时支持自定义数据接入及评测prompt模板定制化。 模型接入:在模型接入上,SecBench同时支持HuggingFace开源模型、大模型API服务、本地部署大模型自由接入,还支持用户自定义模型。 模型评测:在模型评测上,SecBench支持多任务并行,加快评测速度。此外,SecBench已内置多个评估指标以支持常规任务结果评估,也支持自定义评估指标满足特殊需求。 结果输出:在结果输出上,SecBench不仅可以将评测结果进行前端页面展示,还可以输出模型评测中间结果,如配置文件、输入输出、评测结果文件等,支持网络安全大模型研发人员数据分析需求。


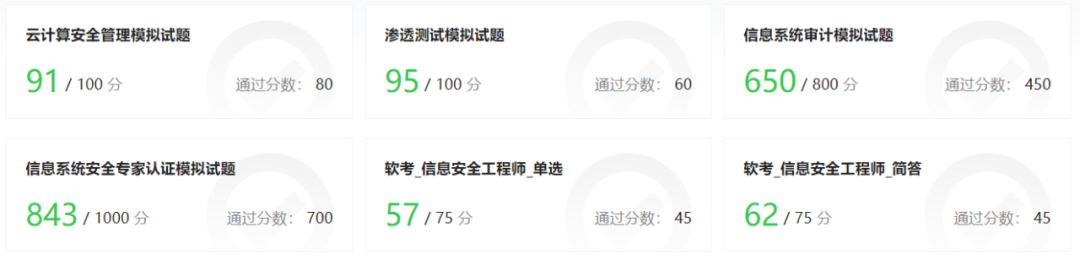
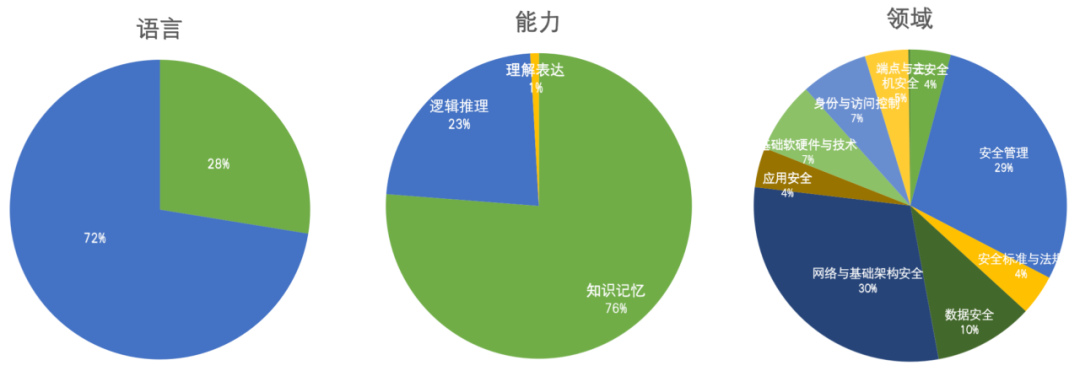
语言维度:覆盖中文、英文两类常见语言的评测。 能力维度:从安全视角,支持大模型对安全知识的知识记忆能力、逻辑推理能力、理解表达能力的评估。 领域维度:支持大模型在不同安全领域能力的评测,包括数据安全、应用安全、端点与主机安全、网络与基础架构安全、身份与访问控制、基础软硬件与技术、安全管理等。 证书考试:SecBench还积累了各类安全证书模拟试题,可支持大模型安全证书等级考试评估。



▶发布 13 年的苹果 iCloud,如何实现存储数十亿个数据库还不卡顿的?
▶字节调整绩效和激励政策,年终奖统一为3个月薪酬;华为发布鸿蒙星河版;微软研究院回应关闭传言 | 极客头条

[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注KnowSafe微信公众号
关注KnowSafe微信公众号随时掌握互联网精彩
赞助链接




