
自2021年6月起,安在征文全新“改版”——“诸子笔会,打卡征文”。简单来说,我们在诸子云社群招募“志愿者”,组成“笔友群”,自拟每月主题,互相督促彼此激励,完成每月一篇原创,在诸子云知识星球做主题相关每日打卡,同时邀请专业作者群内分享,互通交流。我们的目标,不仅是在持续8个月时间里,赢取累计8.8万的高额奖金,更是要探索一种脑力激荡、知识分享的新思路和新玩法。本期发文,即诸子笔会月度主题来稿之一。

中科院心理研究所管理心理学博士,印第安纳大学kelley商学院金融硕士(MF),香港理工大学软件理学与工商管理(MBA)双硕士。前中国移动电子认证中心(CMCA)负责人,OWASP广东区负责人。关注企业数字化过程中网络空间安全风险治理,对大数据、人工智能、区块链等新技术在金融风险治理领域的应用,以及新技术带来的技术风险治理方面拥有丰富的理论和相关经验。
数据安全就像8月深圳的天气,经历6月的预热,7月的炙烤,到达夏季酷热的顶峰,这是源自于6月通过的《数据安全法》,8月三审的《个人信息保护法》以及7月以滴滴为首的系列美国上市企业和数据相关的安全审查引起的社会悸动。当然,数据安全的热点远不是从当下开始,2015年的欧洲GDPR《通用数据保护条例》拉开了隐私保护领域的个人数据和数据跨境的各国竞争立法大幕,2016年中国《网络安全法》第四章网络信息安全包含了重要数据安全领域的规定。之后5年来,无论从法律法规,政策,标准体系上,各部委和社会团体积极开展具体领域的数据安全立法和标准化工作,取得了丰硕的成果。但是,我们也可以看到,在引起社会热度和公众关注之后,数据安全的内涵,外延,在各种场合充斥着不同的理解,解读,有些偏颇,有些误导,有些借势,有些神话。本文仅从数据安全的基本概念,认知的逻辑层次,具体实践过程的部分热点予以简析,希望能够在当下群牤乱舞中保持一丝清净,也希望能抛开数据安全表面的浮躁给予一些脚踏实地的意见。当然,囿于学识与见解,难免偏颇与挂一漏万,因此仅做一家之言,仅供参考。
数据类型 | 拥有主体 | 权利 | 保护法律 | 关注安全需求 |
个人数据 | 个人 | 人身/隐私 | 《数据安全法》
《个人信息保护法》 | 基于隐私保护的设计(PBD)/合规 |
业务数据 | 企业/组织 | 商业机密 | 《商业秘密保护规定》(征求意见稿) |
|
公共数据 | 政府/行业 | 主权 | 《数据安全法》 | 开放的安全性 |
重要数据 | 国家 | 主权 | 《网络安全法》 《数据安全法》 | 合规 |
表一:数据分类
数据分类从拥有主体的角度来分,可分为个人数据,业务数据,公共数据和重要数据。个人数据是跟个人相关的,涉及到个人隐私和个人权利保护的相关数据,也是数据安全领域里最为热点的数据类型,欧洲的GDPR虽然称之为《通用数据保护条例》本质上仍是个人隐私信息即个人数据的保护,目前国内电信欺诈横行与个人数据保护不利密切相关,为了加强黑灰产利用个人数据进行欺诈的网络犯罪打击,国内在个人数据保护领域不断加大监管治理力度,自今年以来,网信办对4批,17类,291款APP进行通报,主要问题包括未经用户同意收集个人信息,违反必要原则,收集与提供与其提供服务无关的个人信息。业务数据是企业和组织在数字化业务或信息化管理过程中的数据,除涉及个人数据,重要数据需要按照相关规定确保合规外,重点关注的是公司商业秘密泄漏带来的安全风险,这个领域是企业谈及数据安全的传统概念时,重点关注的防泄漏领域。公共数据是政府或第三方非盈利组织例如行业协会等,对本行业,本区域的相关数据,对个人,企业的日常活动,经营决策具有帮助作用公共数据,目前也是各级地方政府希望在数据作为生产要素,促进本地化公共数据共享,开放,打造数字之都,形成竞争优势和先发优势的关键竞争力所在。重要数据是在《网络安全法》《数据安全法》中相关关键基础设施保障的同时提出数据安全的关键所在,该类数据的未授权访问与使用可能对国家安全造成重大风险,对企业而言,需要注意涉及到重要数据的合规性要求,避免重要数据的安全风险导致公司承担违法的重要责任。四类数据并不是非此即彼的关系,业务数据与个人数据,重要数据可能存在重叠关系,相应的安全保障措施规划与设计需要从三类数据的安全需求出发,做到全面覆盖。
数据分类 | 数据类型 | 数据源 | 算法 | 应用 | 关注安全需求 |
加工数据 | 第三方数据 | 第三方 |
| 商业机密 | 数据源评估/协议 |
推测数据 | 个人/业务/第三方 | 人工/AI | 隐私/商业机密/主权 | 关联性/可信性 |
统计数据 | 业务/第三方 | 模型 | 商业机密/主权 | 可信性/合规 |
画像数据 | 个人/业务/第三方 | 模型/AI | 隐私 | 算法的可信性/合规 |
表二、加工数据
除了关注原始数据外,在原始数据的基础上形成的加工数据,除了需要按照四类数据分类做好相应保障工作之外,需要关注加工需求和过程中的数据安全保障需求,第三方数据包括购买,合作等模式获取的原始和已加工数据,需要关注第三方数据源的评估,包括数据的准确性,完整性,及时性,对数据交换的协议进行安全性评估。推测数据是通过不同数据的关联分析得到的有价值数据,一方面,需要避免数据匿名化和去标识化带来的聚合分析和关联分析风险,降低推测数据对个人隐私和国家安全可能造成的潜在风险,同时,需要关注推测数据的关联性和可信性,给企业和组织带来的有效价值。统计数据是基于条目数据根据具体模型,得出统计价值的数据,相对于推测数据,模型更清晰与明确,但同样需要对统计数据覆盖的范围,统计数据的有效性可行性进行分析。画像数据是数据通过人工智能相关技术,总结出的特征,可以用于营销,定价,信用评价等领域,因画像数据涉及到热点的大数据杀熟,隐私相关的个性化营销,和平台垄断风险,目前属于监管部门重点关注的领域,同时,画像数据基于人工智能算法模式的算法保密带来的黑盒模式,对算法的可信,可靠涉及到人工智能安全领域范畴,也是这类数据安全评估需要关注的算法安全性问题。因此,谈论数据安全不能局限于个人,企业的视角仅谈论个人隐私保护与商业机密的保护,保障公民隐私权利与商业秘密,也要从国家,行业,经济,社会发展的角度关注公共数据的开放,共享和利用,关注重要数据的生成,采集,存储,应用,分享,销毁过程中涉及到的国家安全风险。同样,不能局限于原始数据的机密性,完整性,可用性保护,也要考虑加工数据的数据源,算法,应用带来的可信,可靠,合规的安全需求。
数据分类问题在第一部分做了初步探讨,当然具体到具体的场景,数据分类可以根据场景,业务重要程度,关注和影响范围进一步调整划分,数据分级是对保护能力要求背景下的分级,关键,重要,普通的三级,绝密,机密,秘密,普通的四级是通过定义的模式划分重要程度,指导安全保障策略的分级实施和落实。目前的数据分类分级存量数据依赖于数据库表扫描的基础上以人工咨询服务的方式进行分类分级的字段梳理,逻辑抽象,分类分级系统往往仅是对数据的梳理和逻辑划分,进行标注,与业务系统未能形成实时的联动,对数据安全的策略缺少相关性和自动化的处置机制,仅能提供安全基线和检查列表,以进行人工的安全审计。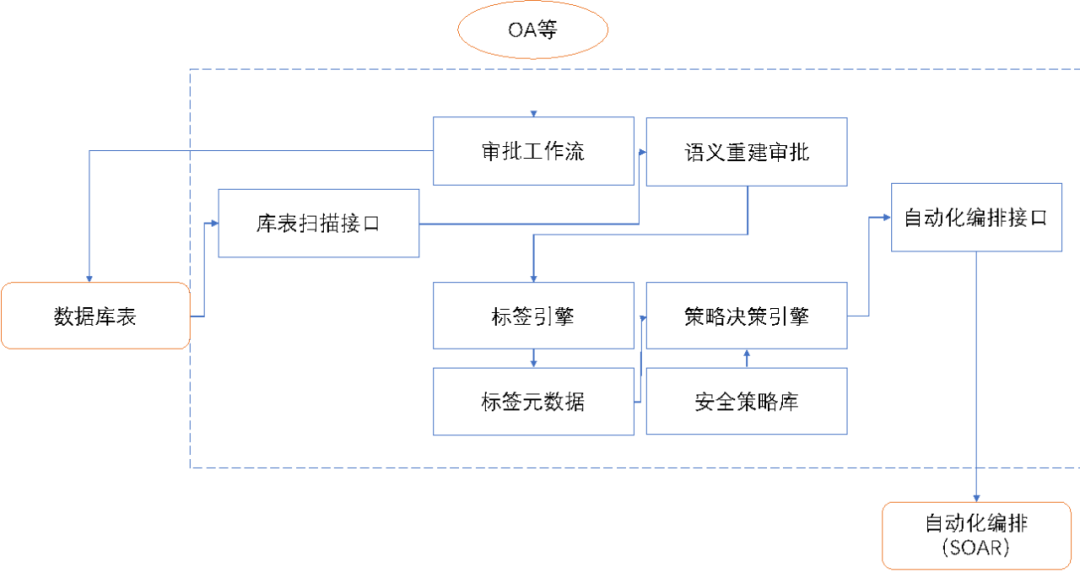
图一、自动化分类分级原型
理想的数据分类分级机制,需要支持对存量数据的分类分级的标签自动化机制,识别和发现数据库表中的数据,并可以通过多标签进行不同维度的分类和分级,对新增数据库表的设计和实施需要具有分类分级标签的审批处置环节,避免缺少数据分类分级的数据库表存在。其中的关键在于语义重建的缓解,这是通过对数据库表的业务价值与含义的定义,根据数据的重要性和影响进行评估,方能确定库表数据的分类分级的准确性,这部分也是分类分级难以自动化的关键所在,安全部门也难以掌握所有数据的业务含义与价值,业务部门的访谈和参与的传统模式容易遗漏缺失和难以持久,通过规则化,自动化结合流程审核的模式,实现语义重建的标签定义和标签化是实现自动化分类分级系统的核心竞争力。数据库表的分类分级标签是数据库表的安全元数据,多标签,和标签的标准化规范化,是标签是否成功支持自动分类分级的基本能力,这和安全策略密切相关,根据安全策略推论分类分级是一种模式,即要避免标签泛滥,失去分类和抽象的本意,也需要避免标签过少,导致安全策略的细分和执行难以区分与落实,这是个循序渐进的持续过程,需要在持续优化中建立适合组织自身的标签库。标签对数据安全保障策略的支持需要数据库分类分级系统与安全自动化编排系统(SOAR)实现联动,对安全策略的定义,安全保障措施的执行,安全策略实施的检查和审计,提供实时的联动措施,真正的实现数据分类分级的自动化以及分类分级对数据安全的策略自动化联动与支撑。分类分级作为数据安全保障实现的基本概念和工具,以及合规的要求普遍得到认可,但在工程实施层面一直备受诟病,这也是因为基础能力缺失造成的,静态的,运动化,人工的,咨询服务式的分类分级,脱离业务实践,在落地的准确性,覆盖的范围,安全保障工作的指导缺少实践价值。因此基于安全数据化(第一期征文),安全自动化(第二期征文)的理念实现自动化分类分级是实现数据安全保障的有力工具。

图二、业务理论视角与技术工程视角的数据安全
在参加互联网安全大会ICS2021的数据安全峰会中,出现了比较有意思的一个争论,数据安全成熟度模型(DSMM)中的数据生命周期保护的模式和基于风险评估的数据体系化安全模式的有效性问题。从大概在2010年第一次讨论数据安全时开始应用数据生命周期保护模式的模型,到这次会议上第一次听到不同意见,还是非常兴奋的,不过论证过程却并没有让我感受到本质的不同,仅是从概念的理解和诠释提出了不同的见解,这还是某安全公司的CEO,公认的圈内大佬的公开发言,说实话,感觉颇有点意气之争的味道。数据安全的需求分析和策略制定,解决方案规划和产品与服务落地,一般不会局限于一个模型和方法,往往会参考不同的方法和模型,综合评价予以取舍,而追求博人眼球,哗众取宠,语不惊人死不休,窃以为并不可取。从个人认知和理解的角度,数据安全生命周期模式可以看作业务和理论视角下的数据安全,关注的是思考数据安全的过程和理论抽象与推导,数据流的风险评估保障体系模型是技术工程视角下的数据安全,关注的是数据在技术体系中的安全保障措施和策略的落地与实践。二者的差异仅在于视角与情景,本质上是从不同维度关注数据安全,而不是非此即彼的竞争。数据作为数字化或信息化的输入和输出,其安全保障可以说是网络安全保障的核心,网络信息安全保障涉及到的方法论,体系和流程,都可以用于数据安全的分析,评估,策略的规划与设计,风险评估的方法和流程自然可以应用于数据安全,基于数据生命周期的保护理念,把数据从生产,采集,存储,应用,共享,销毁的维度进行细分场景的风险评估,对风险分析的体系化,完整性,可操作性是一种理想的思考模式,其价值不容小觑。因此,把数据生命周期保障的理念看作不做风险评估与分析,仅靠堆积分阶段安全策略,失去了数据安全的完整性和体系化,而变成碎片化,割裂化的数据安全的观点,要么是认知层面的问题误解数据生命周期对数据安全保障价值和意义的本意,要么是非此即彼的二分法有意为之的曲解,以建立推崇理论的竞争优势。当然数据流的观念有其价值,从数据实体的静态资产梳理,到数据流动节点的库表、应用、API、接口的元数据全程的追溯管理,在工程实践上建立业务数据与管理数据的分离,利于实时的追踪,监控,审计和追溯,自然具有值得称赞的实践价值,这样的工具和产品在安全自动化领域的发现,控制,检查,预警,处置意义重大,但不足以因数据生命周期保障理论的复杂和落地困难而做出否定的姿态。从理论到实践,从思考到落地,不能顾此失彼。当然,基于威胁建模的模型,基于攻击面分析的模型,基于ATT&CK的框架模型,GDPR的PDIM等同样是实现最佳实践在数据安全领域思考和风险评估的重要依据,在数据安全工程实践中,都是助力思考,查缺补漏,向标杆看齐的有益工具。因篇幅的原因,本文并未对所有问题展开阐述,也未对数据安全涉及到的风险,可以应用的策略,具体的技术实践以及标杆案例进行讨论,计划在8月的打卡计划中抽丝剥茧,予以阐述,待打卡结束,梳理成文,另行分享,以飨读者。



齐心抗疫 与你同在 
在线申请SSL证书行业最低 =>立即申请
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 关注KnowSafe微信公众号
关注KnowSafe微信公众号



