如何处理大体积 XLSX/CSV/TXT 文件?

在开发过程中,可能会遇到这样的需求,我们需要从本地的 Excel 或 CSV 等文件中解析出信息,这些信息可能是考勤打卡记录,可能是日历信息,也可能是近期账单流水。但是它们共同的特点是数据多且繁杂,人工录入的工作量庞大容易出错,需要花费大量时间。那有没有什么方法能自动解析文件并获取有用信息呢?

当这个文件数据量也不是很多的时候,有很多前端工具可供选择。例如 SheetJS,就提供了从 Excel、CSV 中解析出用信息的很多方法,十分方便。
当数据量只是几千条的程度的,选择的余地很多,但是一旦数据量级增加,处理就变得复杂。如果 XLSX/CSV 数据量达到了 100w+ 条,Office、WPS 想打开看一下,都会需要很长的时间。
那又该如何从这样大体积的 Excel/CSV/TXT 中解析出数据呢?
背景
下面我们通过一个假设的需求,来讲述理解整个过程。假设我们需求是从本地 Excel、CSV、TXT(或者其他格式的)文件中解析出数据,并经过清洗后存入本地数据库文件中。但是这些文件体积可能是 5M、50M、500M 甚至更大。那么在浏览器环境下如何上传?Node 环境下应该如何解析?
首先,我们需要了解的是浏览器 Web 页面如何上传大体积文件?
Web 页面如何上传大体积文件?
Web 页面一般也是可以上传大文件的,但是会面临一个问题。如果要上传的数据比较大,那么整个上传过程会比较漫长,再加上上传过程的不确定因素,一旦失败,那整个上传就要从头再来,耗时很长。
面对这个问题,我们可以通过将大文件分成多份小文件,每一次只上传一份的方法来解决。这样即使某个请求失败了,也无需从头开始,只要重新上传失败的那一份就好了。
如果想要使用这个方法,我们需要满足以下几项需求:
大体积文件支持切片上传
可以断点续传
可以得知上传进度
首先看一下如何进行大文件切割。Web 页面基本都是通过 <input type='file' /> 来获取本地文件的。 而通过 input 的 event.target.files 获取到的 file,其实是一个 File 类的实例,是 Blob 类的子类。
Blob 对象表示一个不可变、原始数据的类文件对象。它的数据可以按文本或二进制的格式进行读取,也可以转换成 ReadableStream 来用于数据操作。 简单理解合一将 Blob 看做二进制容器,表示存放着一个大的二进制文件。Blob 对象有一个很重要的方法:slice(),这里需要注意的是 Blob 对象是不可变的,slice 方法返回的是一个新的 Blob,表示所需要切割的二进制文件。
slice() 方法接受三个参数,起始偏移量,结束偏移量,还有可选的 mime 类型。如果 mime 类型,没有设置,那么新的 Blob 对象的 mime 类型和父级一样。而 File 接口基于 Blob,File 对象也包含了slice方法,其结果包含有源 Blob 对象中指定范围的数据。
看完了切割的方法,我们就可以对二进制文件进行拆分了。拆分示例如下:
function sliceInPiece(file, piece = 1024 * 1024 * 5) {let totalSize = file.size; // 文件总大小let start = 0; // 每次上传的开始字节let end = start + piece; // 每次上传的结尾字节let chunks = []while (start < totalSize) {// 根据长度截取每次需要上传的数据// File对象继承自Blob对象,因此包含slice方法let blob = file.slice(start, end);chunks.push(blob)start = end;end = start + piece;}return chunks}
获得文件切割后的数组后,就可以挨个调用接口上传至服务端。
let file = document.querySelector("[name=file]").files[0];const LENGTH = 1024 * 1024 * 0.1;let chunks = sliceInPiece(file, LENGTH); // 首先拆分切片chunks.forEach(chunk=>{let fd = new FormData();fd.append("file", chunk);post('/upload', fd)})
完成上传后再至服务端将切片文件拼接成完整文件,让 FileReader 对象从 Blob 中读取数据。
当然这里会遇到两个问题,其一是面对上传完成的一堆切片文件,服务端要如知道它们的正确顺序?其二是如果有多个大体积文件同时上传,服务端该如何判断哪个切片属于哪个文件呢?
前后顺序的问题,我们可以通过构造切片的 FormData 时增加参数的方式来处理。比如用参数 ChunkIndex 表示当前切片的顺序。
而第二个问题可以通过增加参数比如 sourceFile 等(值可以是当前大体积文件的完整路径或者更严谨用文件的 hash 值)来标记原始文件来源。这样服务端在获取到数据时,就可以知道哪些切片来自哪个文件以及切片之间的前后顺序。
如果暂时不方便自行构架,也可以考虑使用云服务,比如又拍云存储就支持大文件上传和断点续传的。比如:
断点续传
在上传大文件或移动端上传文件时,因为网络质量、传输时间过长等原因造成上传失败,可以使用断点续传。特别地,断点续传上传的图片不支持预处理。特别地,断点续传上传的文件不能使用其他上传方式覆盖,如果需要覆盖,须先删除文件。
名称概念
文件分块:直接切分二进制文件成小块。分块大小固定为 1M。最后一个分块除外。
上传阶段:使用 x-upyun-multi-stage 参数来指示断点续传的阶段。分为以下三个阶段: initate(上传初始化), upload(上传中), complete(上传结束)。各阶段依次进行。
分片序号:使用 x-upyun-part-id 参数来指示当前的分片序号,序号从 0 起算。
顺序上传:对于同一个断点续传任务,只支持顺序上传。
上传标识:使用 x-upyun-multi-uuid 参数来唯一标识一次上传任务, 类型为字符串, 长度为 36 位。
上传清理:断点续传未完成的文件,会保存 24 小时,超过后,文件会被删除。
可以看到,云存储通过分片序号 x-upyun-part-id 和上传标识 x-upyun-multi-uuid 解决了我们前面提到的两个问题。这里需要注意的是这两个数据不是前端自己生成的,而是在初始化上传后通过 responseHeader 返回的。
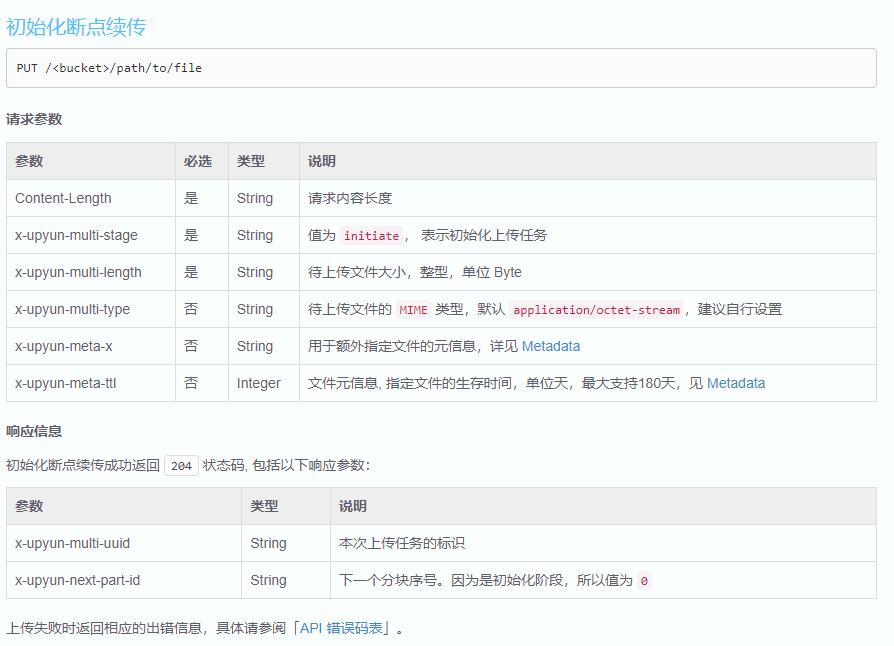
△ 又拍云初始化断点续传
前文说的都是使用 Web 页面要如何上传大文件。接下来我们来看看 NodeJS 是如何解析、处理这类大体积文件呢?
NodeJS 解析大体积文件
首先需要明确一个概念 NodeJS 里没有 File 对象,但是有 fs(文件系统) 模块。fs 模块支持标准 POSIX 函数建模的方式与文件系统进行交互。
POSIX 是可移植操作系统接口 Portable Operating System Interface of UNIX 的缩写。简单来说 POSIX 就是在不同内核提供的操作系统下提供一个统一的调用接口,比如在 linux 下打开文件和在 widnows 下打开文件。可能内核提供的方式是不同的,但是因为 fs 是支持 POSIX 标准的,因此对程序猿来说无论内核提供的是什么,直接在 Node 里调 fsPromises.open(path, flags[, mode]) 方法就可以使用。
这里简单用 Vue 举例说明。Vue 在不同的环境下比如 Web 页面或 Weex 等等的运行生成页面元素的方式是不同的。比如在 Web 下的 createElement 是下方这样:
export function createElement (tagName: string, vnode: VNode): Element {const elm = document.createElement(tagName)if (tagName !== 'select') {return elm}// false or null will remove the attribute but undefined will notif (vnode.data && vnode.data.attrs && vnode.data.attrs.multiple !== undefined) {elm.setAttribute('multiple', 'multiple')}return elm}
在 Weex 下则是如下情况:
export function createElement (tagName: string): WeexElement {return document.createElement(tagName)}
以上两种情况下的 createElement 是不一样的。同理,还有很多其他的创建模块或者元素的方式也是不同的,但是针对不同平台,Vue 提供了相同的 patch 方法,来进行组件的更新或者创建。
import * as nodeOps from 'web/runtime/node-ops'import { createPatchFunction } from 'core/vdom/patch'import baseModules from 'core/vdom/modules/index'import platformModules from 'web/runtime/modules/index'// the directive module should be applied last, after all// built-in modules have been applied.const modules = platformModules.concat(baseModules)// nodeops 封装了一系列DOM操作方法。modules定义了一些模块的钩子函数的实现export const patch: Function = createPatchFunction({ nodeOps, modules })
△ Web 平台下的情况
import * as nodeOps from 'weex/runtime/node-ops'import { createPatchFunction } from 'core/vdom/patch'import baseModules from 'core/vdom/modules/index'import platformModules from 'weex/runtime/modules/index'// the directive module should be applied last, after all// built-in modules have been applied.const modules = platformModules.concat(baseModules)export const patch: Function = createPatchFunction({nodeOps,modules,LONG_LIST_THRESHOLD: 10})
△ weex 平台下的情况
这样,无论运行环境的内部实现是否不同,只要调用相同的 patch 方法即可。而 POSIX 的理念是与上面所举例的情况是相通的。
简单了解了 POSIX,我们回到 fs 模块。fs 模块提供了很多读取文件的方法,例如:
fs.read(fd, buffer, offset, length, position, callback)读取文件数据。要操作文件,得先打开文件,这个方法的fd,就是调用 fs.open 返回的文件描述符。
fs.readFile(path[, options], callback) 异步地读取文件的全部内容。可以看做是fs.read的进一步封装。
使用场景如下:
import { readFile } from 'fs';readFile('/etc/passwd','utf-8', (err, data) => {if (err) throw err;console.log(data);});
因为 fs.readFile 函数会缓冲整个文件,如果要读取的文件体积较小还好,但是如果文件体积较大就会给内存造成压力。那有没有对内存压力较小的方式来读取文件呢?
有的,我们今天的主角 stream 流登场。
stream
stream 流是用于在 Node.js 中处理流数据的抽象接口。 stream 模块提供了用于实现流接口的 API。流可以是可读的、可写的、或两者兼而有之。
fs 模块内有个 fs.createReadStream(path[, options])方法,它返回的是一个可读流,默认大小为 64k,也就是缓冲 64k。一旦内部读取缓冲区达到这个阈值,流将暂时停止从底层资源读取数据,直到消费当前缓冲的数据。
消费数据的方法可以是调 pipe() 方法,也可以被事件直接消费。
// pipe 消费readable.pipe(writable)// 或者// 事件消费readable.on('data', (chunk) => {writable.write(chunk);});readable.on('end', () => {writable.end();});
除了可读流,也有可写流 fs.createWriteStream(path[, options]), 可以将数据写入文件中。
好了,所需要的前置知识基本就介绍完毕了,回到正题。假如我们有一个文件夹,里面存放着数十个 XLSX/CSV 文件,且每一个体积都超过了 500M。那该如何从这些文件中读取信息,并写入数据库文件中呢?
批量解析 CSV 文件
假设我们需要解析的文件路径已经是知道的,可以通过路径获取到文件,那么将这些路径存入一个数组并命名为 needParseArr,我们需要按照顺序一个个解析这些 CSV、XLSX 文件信息,并清洗然后写入数据库。
首先,是一个个读的逻辑 (readOneByOne)。
async readOneByOne () {try {for (let i = 0; i < needParsePathArr.length; i++) {const filePath = needParsePathArr[i]console.log(`解析到第${i}个文件,文件名:${filePath}`)await streamInsertDB(filePath)}} catch (err) {}}
streamInsertDB 是我们的主要逻辑的入口。
async function streamInsertDB (filePath) {return new Promise((resolve, reject) => {const ext = path.extname(filePath)// 判断了下文件类型if (ext === '.csv') {// 解析csvparseAndInsertFromCSV(filePath, resolve, reject)} else if (ext === '.xlsx') {// 自执行函数(async function getName () {try {// 先转换成csv。也可以不转换,直接解析xlsx,后文会详细解释。const csvFileName = await convertXlsx2Csv(filePath)// 复用解析csv的逻辑parseAndInsertFromCSV(csvFileName, resolve, reject)} catch (error) {reject(`error: ${error.message || error}`)}})()}})}
parseAndInsertFromCSV 中就是使用我们前面所提到的知识点的主要阵地。下面简单介绍一下各个函数:
chardet:这个函数的作用是监测 CSV 文件的编码格式的,毕竟不是每个 CSV 都是 UTF-8 编码,带中文的 CSV 编码类型可能是 GBK 或者 GB18030、GB18031 等等,这种格式不经过处理直接读取,中文会显示为乱码。所以需要执行转换的函数 iconv 转换一下。
pipe:可以用来建立管道链,可以理解为 pipe 的作用就像一个管道,可以对目标流边读边写,这里我们是一边解码一边重新编码。
insertInBlock:这个函数是获取到一定数量的数据后(本例中是从 CSV 中解析出 3 万条左右数据的时候),暂停一下来执行一些操作,比如写入数据库或者对里面的数据进行过滤、处理等等,根据实际需要来定。
csv:这个函数的作用就是读出流中的具体数据的。
具体逻辑解释可以看注释。
const chardet = require('chardet');const csv = require('fast-csv'); // 比较快解析csv的速度的工具const iconv = require('iconv-lite');const arrayFromParseCSV = [] // 存放解析出来的一行行csv数据的let count = 0 // 计数// resolve, reject 是外部函数传进来的,用以判断函数执行的状态,以便正确的进行后续逻辑处理function parseAndInsertFromCSV (filePath, resolve, reject) {const rs = fs.createReadStream(filePath) // 创建可读流// 这里的防抖和柯里化const delayInsert = debounce((isEnd, cb = () => {}) => insertInBlock(isEnd, cb, rs, resolve, reject), 300)/// sampleSize: 5120 表示值读取文件前5120个字节的数据,就可以判断出文件的编码类型了,不需要全部读取chardet.detectFile(filePath, { sampleSize: 5120 }).then(encoding => {// 如果不是UTF-8编码,转换为utf8编码if (encoding !== 'UTF-8') {rs.pipe(iconv.decodeStream(encoding)).pipe(iconv.encodeStream('UTF-8')).pipe(csv.parse({ header: false, ignoreEmpty: true, trim: true })) // 解析csv.on('error', error => {reject(`解析csv error: ${error}`)}).on('data', rows => {count++ // 计数,因为我们要分块读取和操作arrayFromParseCSV.push(rows) // 读到就推送到数组中if (count > 30000) { // 已经读了30000行,我们就要先把这3w行处理掉,避免占用过多内存。rs.pause() // 暂停可读流delayInsert(false) // false 还没有结束。注意:即使rs.pause, 流的读取也不是立即暂停的,所以需要防抖。}}).on('end', rowCount => {console.log(`解析完${filePath}文件一共${rowCount}行`)delayInsert(true, () => {rs.destroy() // 销毁流resolve('ok') // 一个文件读取完毕了})})}})}
清洗数据和后续操作的逻辑在 insertInBlock 里。
function insertInBlock (isEnd, cb, filePath, resolve, reject) {const arr = doSomethingWithData() // 可能会有一些清洗数据的操作// 假如我们后续的需求是将数据写入数据库const batchInsert = () => {batchInsertDatabasePromise().then(() => {if (cb && typeof cb === 'function') cb()!isEnd && rs.resume() // 这一个片段的数据写入完毕,可以恢复流继续读了})}const truely = schemaHasTable() // 比如判断数据库中有没有某个表,有就写入。没有先建表再写入。if (truely) { //batchInsert()} else {// 建表或者其他操作,然后再写入doSomething().then(() => batchInsert())}}
这样,解析和写入的流程就完成了。虽然很多业务上的代码进行了简略,但实现上大体类似这个流程。
批量解析 XLSX 文件
转化成 CSV?
在前面的代码实例中,我们利用了利用可写流 fs.createWriteStream 将 XLSX 文件转换成 CSV 文件然后复用解析 CSV 。这里需要注意的是,在将数据写入 CSV 格式文件时,要在最开始写入 bom 头 \ufeff。此外也可以用 xlsx-extract 的 convert 函数,将 XLSX 文件转换成 TSV。
const { XLSX } = require('xlsx-extract')new XLSX().convert('path/to/file.xlsx', 'path/to/destfile.tsv').on('error', function (err) {console.error(err);}).on('end', function () {console.log('written');})
可能有人会疑惑,不是 CSV 么,怎么转换成了 TSV 呢?
其实 tsv 和 CSV 的区别只是字段值的分隔符不同,CSV 用逗号分隔值(Comma-separated values),而 TSVA 用的是制表符分隔值 (Tab-separated values)。前面我们用来快速解析 CSV 文件的 fast-csv 工具是支持选择制表符\t作为值的分隔标志的。
import { parse } from '@fast-csv/parse';const stream = parse({ delimiter: '\t' }).on('error', error => console.error(error)).on('data', row => console.log(row)).on('end', (rowCount: number) => console.log(`Parsed ${rowCount} rows`));
直接解析?
那是否可以不转换成 CSV,直接解析 XLSX 文件呢 ?其实也是可行的。
const { xslx } = require('xlsx-extract') // 流式解析xlsx文件工具// parser: expat, 需要额外安装node-expat,可以提高解析速度。new XLSX().extract(filePath, { sheet_nr: 1, parser: 'expat' }).on('row', function (row) {// 每一行数据获取到时都可以触发}).on('error', function (err) {// error});
但是这种方式有一个缺陷,一旦解析开始,就无法暂停数据读取的流程。xlsx-extract 封装了 sax,没有提供暂停和继续的方法。
如果我们直接用可读流去读取 XLSX 文件会怎么样呢?
const readStream = fs.createReadableStream('path/to/xlsx.xlsx')可以看到现在流中数据以 buffer 的形式存在着。但由于 xlsx 格式实际上是一个 zip 存档的压缩格式,存放着 XML 结构的文本信息。所以可读流无法直接使用,需要先解压缩。
解压缩可以使用 npm 包 unzipper 。
const unzip = require('unzipper')const zip = unzip.Parse();rs.pipe(zip).on('entry', function (entry) {console.log('entry ---', entry);const fileName = entry.path;const { type } = entry; // 'Directory' or 'File'const size = entry.vars.uncompressedSize; // There is also compressedSize;if (fileName === "this IS the file I'm looking for") {entry.pipe(fs.createWriteStream('output/path'));} else {entry.autodrain();}})
现在我们已经解压了文件。
前面提到,xlsx-extract 是 封装了 sax,而 sax 本身就是用来解析 XML 文本的,那我们这里也可以使用 sax 来对可读流进行处理。
sax 解析的源码可以看这里,大致是根据每一个字符来判断其内容、换行、开始、结束等等,然后触发对应事件。
const saxStream = require('sax').createStream(false);saxStream.on('error', function (e) {console.error('error!', e);});saxStream.on('opentag', function (node) {console.log('node ---', node);});saxStream.on('text', (text) => console.log('text ---', typeof text, text));
最后将两者结合起来:
const unzip = require('unzipper');const saxStream = require('sax').createStream(false);const zip = unzip.Parse();saxStream.on('error', function (e) {console.error('error!', e);});saxStream.on('opentag', function (node) {console.log('node ---', node);});saxStream.on('text', (text) => {console.log('text ---', typeof text, text)});rs.pipe(zip).on('entry', function (entry) {console.log('entry ---', entry);entry.pipe(saxStream)})
使用本地的 XLSX 文件测试后,控制台打印出以下信息:

这些信息对应着 XLSX 文档里的这部分信息。Node 里打印的 ST SI,代表着 xml 的标签。

这样,其实我们也拿到了 XLSX 里的数据了,只不过这些数据还需要清洗、汇总、一一对应。同时由于我们是直接在可读流上操作,自然也可以 pause、resume 流,来实现分块读取和其他操作的逻辑。
总结
对体积较小的 XLSX、CSV 文件,基本 SheetJS 就可以满足各种格式文件的解析需求了,但是一旦文档体积较大,那么分片、流式读写将成为必不可少的方式。
通过前面例子和代码的分解,我们可以了解这类问题的解决办法,也可以拓展对类似需求的不同解决思路。一旦我们能对大体积文件的分块处理有一定的概念和了解,那么在遇到类似问题的时候,就知道实现思路在哪里了。
快 来 找 又 小 拍

推 荐 阅 读 


设为星标

更新不错过
设为星标
更新不错过
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注KnowSafe微信公众号
关注KnowSafe微信公众号随时掌握互联网精彩




