硬货来了,RTE2022 大会技术专场:人性化、软硬件结合

硬货来了!最近由声网主办的 RTE2022 第八届实时互联网大会召开,大会为期四天,其中第二天是开发者日,今年大会设置了音频、视频、RTE 云、最佳实践、开源五个技术主题论坛,邀请了如 Cocos、Netint、OPPO、Rokid、笨笨网络科技、迷听科技、上海大学、声网、思必驰、天准、网易云音乐、微软亚洲研究院、西北工业大学、熹乐科技、小红书、烟台小樱桃网络科技、中国科学院声学研究所的数十位产研技术专家,分享研究实践工作。
笔者看完开发者日的最大感受是,技术专场延续了 RTE 大会一贯的技术风格,全程都是硬核前沿技术的干货分享,就像听完了一系列的实时音视频专业技术课程,收获满满。

音视频研究的方向:更有“人味”
音频和视频技术是 RTE 最重要的两块技术分支,RTE2022 大会第一天的主会演讲上,声网创始人兼 CEO 赵斌就介绍了空间音频的内容。技术专场里,声网音频算法工程师李嵩详细介绍了空间音频的技术原理和工程落地,比如直达头部声音的相关函数、音源的朝向和距离特性,对空间音频的渲染等等。

声网音频算法工程师李嵩分享空间音频的技术实现(截取演讲 PPT 内容)
空间音频让人对声音的感受更丰富,是除了旋律之外,一种用 IT 技术讲述“声音的故事”的新方式。这将是对音频技术重要的一个探索方向,对于开发者和最终用户,其实也提供了更大的想象空间。李嵩也介绍了空间音频应用的场景,除了游戏、社交、元宇宙,在线会议、在线教育等场景也会用到空间视频,几乎是包含了所有 RTE 可能的场景。
音频另一个主流的技术研究方向是声音降噪。技术专场除了嘉宾们分享 AI 深度学习、神经网络等对降噪效果的实践和精进,另一个让笔者印象深刻的演讲,是西北工业大学谢磊教授分享在降噪研究中,如何对语谱不造成损伤,缓解语音过度抑制的问题。
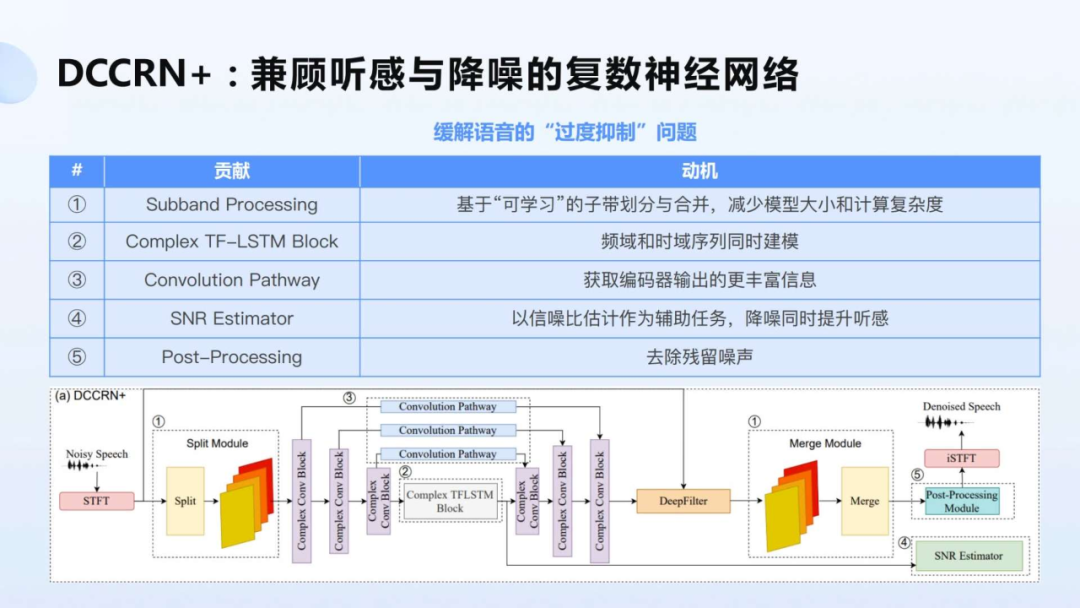
西北工业大学谢磊教授分享团队推出的 DCCRN+,兼顾听感和降噪
举个例子更好理解过度抑制是什么,谢磊教授演示了团队在吵闹的大街上讲话的录音,降噪处理之后,“过度”去除了环境里的汽车行驶、鸣笛的声音,说话者描述环境时(如周围很吵很热)人们却听不出说话者所处环境(当然,这要看声音内容的用途而定)。谢磊教授团队推出了 DCCRN+,希望兼顾听感和降噪。就像技术专场一位嘉宾提到的,技术实践的目标,是让音视频更有“人味”,这可能是场景探索中,对用户体验更贴切和直观的形容词。

视频走向高清、超高清
在视频技术专场论坛里,技术专家们分享了超高清视频技术的研究。第一天主会中赵斌也提到了 RTE 主流分辨率可能会上升到 720p,声网视频算法工程师张倚豪在技术专场详细介绍了 RTE 场景下高清能力迭代升级的关键技术,他分享了基于 H.265 视频编码标准,声网的技术方案解析,这也是技术对视觉体验的持续精进和追求。

软硬件结合,加速音视频优化
技术专场上音频和视频技术的另一个重要的趋势,是对音视频数据的软件优化之外,进一步开始探索对音视频相关元器件和软件算法的结合研究。例如迷听科技 CEO 邓滨介绍麦克风声学结构、仿真、算法演进。其实,音频的输入和输出设备很多,这次邓滨老师介绍的只是一些基础知识,毕竟软硬件结合是非常新的研究方向,值得开发者去重点关注。

在视频方面,智能芯片方案厂商 Netint 技术市场高级总监 Jan Ozer 更是直接对比了 CPU、GPU、FPGE、ASCI 用于视频方案的参数和性价比,非常直观。

除了对硬件的研究和分析,笨笨网络科技产品负责人何志雄、声网 AI 算法工程师还从 2D 对面部、人体的动作捕捉,进行了分享。以往我们对于 3D 视频动作捕捉,都是需要专业设备例如 ARKit 的 3D 摄像头,并不利于技术和应用的普及使用。通过普通的手机(单目摄像头),在低端手机、轻量化的方案之上,实现更好的视频帧率和还原效果。

笨笨网络科技的面部解决方案效果
除了探索软硬件结合优化,业界还在研究基于更基础的普通设备(例如低端的手机)如何为音视频加速,提高音视频体验。

第一天主会上,声网 CTO&首席科学家钟声提到了声网正在做的三维重建实现个性化的人脸、人体模型。在第二天的技术专场里,声网 AI 算法工程师王丽就详细分享了基于单目(2D)重建人体 3D 模型的研究进展。她介绍了声网探索 2D 和 3D 特征及⽬标之间的关联关系,如何提⾼⽹络模型精确度,最终可以在没有任何 3D 标注数据的情况下进⾏训练。

SD-RTN、技术保障 5 个“9”,打造实时互动边缘云
另外对于音视频的网络传输,今年大会和以往不同的,是技术专场上声网首次对外披露了 RTE 后端的技术实践,声网云原生边缘计算团队负责人王浩宇带来了《RTE 场景下的 Serverless 架构挑战与实践》的主题演讲。
我们都知道实时音视频的应用场景越来越广泛,这些复杂的场景和应用之下,都需要稳定高效、弹性的网络基础设施去支撑。这背后就是声网在构建的支持异构架构、去中心化,不依赖专线实现可靠传输。并且声网继续用 Severless 驱动和支持上层有状态的实时流业务的场景创新。
另外赵斌在大会第一天的主题演讲里分享了声网在 2015 年推出的软件定义虚拟实时网络 SD-RTN,现在的 QoS 服务保障已经保障到了“5 个 9”(99.999%)。技术专场上,声网 RTC 媒体服务器架构师庞博分享了 SD-RTN 架构的演进,目前已经能够支持同一频道超过千人的实时互动场景。另外声网云平台研发负责人朱仁琪也在技术专场分享了声网自研传输层协议 AUT 的演进之路。
每年的 RTE 大会,开发者都能看到实时音视频领域的前沿技术干货,今年也不例外。技术嘉宾们分享了对音视频场景的进一步细致和人性化的探索,另外,以往的音视频技术注重于软件层面的算法调优,这次 RTE 技术专场更具有前瞻视角地,分享了实时音视频领域软硬件技术优化的初步探索。所有这些,都值得开发者进一步了解,CSDN 也将持续关注和报道实时音视频技术发展。
[广告]赞助链接:
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 关注KnowSafe微信公众号
关注KnowSafe微信公众号随时掌握互联网精彩
- XML陷阱:关键的Struts 2漏洞CVE-2025-68493暴露数据
- 多域名SSL证书能保护多少个域名?
- 谷歌发布Android 2月例行安全更新 修复已被黑客利用的高危安全漏洞
- RustDesk开源的远程桌面软件
- 乱下载软件致MBR锁机,逆向分析自救
- 苹果发布 AirPods | 历史上的今天
- “53 岁的我都退休了,但好想跨行当一名程序员,结果收到了 3 份 Offer!”
- 诸子笔会2022 | 王忠惠:安全没有神秘感,但处处是错觉
- 看雪·众安 2021 KCTF 秋季赛 | 第五题设计思路及解析
- 消灭碎片化,Android 内核开发采取“上游优先”策略!
- CSO说安全 | 廖位明:信息安全建设思考
- 为什么我们很难看到代码 5 分钟前的样子?




